
 搜索
搜索

捷报频传!持续发力!
智能机器人与先进制造创新学院科技工作者
多个领域多点开花、成果丰硕
小编整理了新鲜出炉的科研速递
一键解锁最新硬核突破!
——学术论著——
1. 可信具身智能研究院《Advances in Artificial Intelligence》:面向高效与可信人工智能的前沿研究专著出版
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院联合A*STAR、RIKEN、ETH Zürich 等国际科研机构,在人工智能高效学习与可信智能系统方向取得阶段性成果,相关学术专著 Advances in Artificial Intelligence: Efficiency, Reliability, and Innovations in Machine Learning to Healthcare, and Blockchain 由国际知名出版社 Springer Nature 正式出版,并收录于 Springer Adaptation, Learning, and Optimization 系列。本书围绕高效、可靠与可信人工智能主题,系统汇集了机器学习、医疗人工智能、联邦学习、区块链以及大语言模型安全等方向的最新研究进展。
随着人工智能技术在现实世界中的广泛部署,如何兼顾模型性能、计算效率、隐私保护与系统安全,已成为当前 AI 发展的关键挑战。本书从理论建模、算法设计到实际应用多个层面,探讨了下一代智能系统的发展路径。全书共分为四大部分:第一部分聚焦张量模型与高效机器学习,重点研究低秩表示、联邦张量分解与可解释学习;第二部分围绕医疗基础模型,探讨深度学习与多模态 AI 在皮肤病诊断、心律失常预测与心理健康分析中的应用;第三部分关注区块链与人工智能融合,研究联邦学习中的分布式协同、安全共享与隐私保护机制;第四部分则聚焦大语言模型(LLMs)的安全与可靠性问题,包括安全对齐、鲁棒优化以及对抗攻击与越狱防御等前沿方向。本书由复旦大学可信具身智能研究院研究员张景锋联合多位国际青年学者共同担任主编,汇聚来自亚洲、欧洲与大洋洲多个研究机构的研究成果。书中不仅涵盖人工智能基础理论与算法创新,也强调 AI 系统在真实场景中的可靠部署与伦理安全,为可信人工智能的发展提供了系统性的研究视角。此外,本书还特别关注联邦学习、分布式智能与多智能体系统等新兴方向,强调在数据隐私与安全约束下构建可扩展 AI 系统的重要性。相关成果对于推动医疗智能、区块链智能协同以及安全大模型的发展具有重要参考价值,也为未来构建更加高效、安全、可信的人工智能系统提供了新的理论与实践基础。

编 辑 作 者 : Jingfeng Zhang, Joey Zhou, Rosa Qi Yue So, Takaharu Yaguchi, Kentaroh Toyoda, Andong Wang, Peilun Dai, Haotong Qing, Xingyu Zheng
著作链接:https://link.springer.com/book/10.1007/978-3-032-12362-6
——学术论文——
1.集群机器人系统实验室Advanced Science封面文章:仿生自适应腿爪赋能无人机:让飞行机器人像鸟一样稳定栖息与抓取

近日,我院集群机器人系统实验室(简称MAGIC Lab)甘中学教授、朱国牛青年副研究员与新加坡南洋理工大学I-Ming Chen教授团队合作在无人机栖息与抓取领域取得新进展,相关成果以“Bioinspired Adaptive Leg-Claw Enables Robust Perching and Grasping for UAVs”为题发表于国际知名权威期刊Advanced Science,并被遴选为封面文章。
传统无人机在执行任务时,通常依赖起落架进行简单着陆,但在树枝、岩壁、管道等非结构化环境中,难以实现稳定停靠或持续作业。而自然界中的鸟类则展现出高度灵活的腿爪协同机制,能够在不同粗细、不同材质的支撑物上稳定栖息,并快速调整抓握姿态。这种兼具飞行、栖息与抓取能力的运动模式一直是飞行机器人研究的重要灵感来源。受此启发,研究团队设计了一种具备自适应调节能力的仿生腿爪系统,通过机械构型与柔顺接触设计,使无人机能够像鸟类一样实现稳定栖息与可靠抓取,为空中机器人环境交互能力的发展带来了新的突破。


该系统的核心在于腿部缓冲调节与爪部多自由度贴合的协同机制。其中,自适应腿部结构在接触瞬间吸收冲击能量,降低无人机姿态扰动,提高着陆稳定性;多指爪式抓取机构可根据目标几何形态自动调整包络角度,实现对不规则结构的可靠贴附;被动-主动耦合控制策略可减少复杂控制负担,使系统在低计算资源条件下仍保持稳定性能。此外,整个机构针对飞行平台进行了轻量化优化。在完成抓取后,系统可利用机械锁定效应保持稳定抓握,大幅降低持续驱动带来的能量消耗,为长时间栖息创造条件。实验结果表明,该结构在面对树枝、立柱、墙面边缘等多类型支撑物时,均表现出良好的适应能力与重复抓取稳定性。该研究的意义不仅在于提升无人机的停靠能力,更重要的是推动无人机从单纯的飞行平台向具备环境交互能力的机器人系统转变。随着具身智能与仿生机器人技术的发展,无人机系统正从飞行器逐步演化为可行动、可抓取、可交互的智能体。本研究所提出的自适应腿爪系统,为未来构建高机动性空中机器人提供了重要设计范式。
论文第一作者为2024级硕士生程天宇,我院甘中学教授与朱国牛青年副研究员为论文的通讯作者。
原文链接:https://advanced.onlinelibrary.wiley.com/doi/full/10.1002/advs.202523518
2.智柔体设计与制造实验室徐凡教授团队Journal of the Mechanics and Physics of Solids:构建活性杆动力学模型揭示线虫多模态运动机制
近日,复旦大学智柔体设计与制造实验室徐凡教授团队在生物启发微软机器人动力学领域取得新进展。研究团队结合形态弹性与Cosserat杆理论,通过变形梯度乘法分解将肌肉驱动与自发曲率演变定量关联,构建了活性杆动力学模型,揭示了秀丽隐杆线虫(C. elegans)肌肉驱动与形态演变及自适应运动之间的调控机制,为仿生微软机器人的理性设计提供了理论基础。相关工作以Active filament dynamics model for the locomotion of C. elegans and soft microrobots为题发表于国际固体力学旗舰期刊《Journal of the Mechanics and Physics of Solids》。

智能机器人与先进制造创新学院/航空航天系硕士生胡文润为论文第一作者,复旦大学徐凡教授和同济大学汪婷助理教授为论文共同通讯作者。巴黎高等师范学院Martine Ben Amar教授和同济大学杨伟东教授是论文的合作者。研究得到国家自然科学基金委、首批上海市基础研究特区计划、上海市教委等资助。
原文链接:https://doi.org/10.1016/j.jmps.2026.106656
3.郭睿倩课题组Advanced Science:100%量子产率!高熵量子点复合光子晶体用于信息加密

近日,我院光源与照明工程系郭睿倩课题组联合高分子系汪长春教授课题组,在环保高性能发光量子点与光学信息加密领域取得突破性研究进展。相关成果以“Unity Quantum Yield of High-Entropy Quantum Dots Composited With Photonic Crystals for Information Encryption”为题,发表在综合科学领域权威期刊Advanced Science上。
该研究首次将高熵范式拓展至I-III-VI族量子点体系,攻克传统合金量子点发光效率受限难题。团队采用一锅成核策略结合分步热注入壳层包覆技术,成功合成CuZnCrGaSe/ZnSe/ZnS核/壳/壳高熵量子点;通过优化反应参数、元素配比,并依托ZnSe/ZnS精准双壳层高效钝化表面缺陷,使量子点发射波长达到540 nm,实现创纪录的100%光致发光量子产率(PLQY),创下目前I-III-VI族合金量子点的最高量子产率纪录。研究进一步将该高性能高熵量子点与刺激响应型光子晶体复合,制备出可在日光结构色与紫外荧光色间可逆切换的双模复合薄膜,依托量子点发光与光子晶体带隙的协同调控实现信息加密,并通过可视化二进制编解码系统完成安全加密验证,为开发环保、高稳定、高安全性的光学加密防伪材料提供了全新技术路线。
我院2023级博士生黄茂源为该论文第一作者,我院郭睿倩研究员与梅时良青年副研究员为论文的通讯作者。该工作得到了国家重点研发计划、国家自然科学基金、上海市自然科学基金等项目资助。
文章链接:https://doi.org/10.1002/advs.75603
4.仿生结构与机器人实验室Advanced Science:折纸为躯,蠕虫为灵——多模态管道机器人突破复杂工业管道“最后一公里”巡检难题
近日,我院仿生结构与机器人实验室与复旦大学义乌研究院、河海大学联合研究团队在折纸仿蠕虫多模态管道机器人领域取得重要进展,相关成果以《 A Worm-Inspired Origami Robot with Multimodal Locomotion for Adaptive Mobility in Complex Pipeline Environments》(一种面向复杂管道环境、具备多模态运动能力的仿蠕虫折纸机器人)为题,发表于国际知名权威期刊Advanced Science。该论文的共同第一作者为复旦大学义乌研究院青年研究员张琦炜与复旦大学智能机器人与先进制造创新学院博士生谭康宁,通讯作者为方虹斌教授,王延杰教授(河海大学)与徐鉴教授(复旦大学)参与指导。

研究团队受蠕虫运动模式与折纸可变形结构的双重启发,成功研发出一款高度集成的多模态管道机器人。该机器人系统集成了 8 个基于 Yoshimura 折纸构型的气动蠕动模块、2 个配备可展开翻板的滚动模块,以及 1 个由形状记忆合金(SMA)驱动的 Waterbomb 折纸抓取模块。通过建立统一的步态生成框架,机器人可参数化生成包括仿蚯蚓直线/侧向/圆周运动、尺蠖式运动以及双向滚动在内的 25 种运动步态,并能根据环境需求平稳切换。实验验证表明,该机器人能够在倾斜管、弯管、变径管及存在间隙的断续管道等复杂工业环境中实现稳定穿越与自适应运动。同时,头部集成的抓取模块可对不同刚度(如沙袋、海绵、橙皮)的物体进行有效抓取和吞咽式操控,搭载的摄像头还能实时回传管道内部视觉信息,为远程检测与控制提供关键反馈。
这一工作首次通过统一的步态生成框架与模块化折纸设计,破解了管道机器人“能进入的无法高效移动、能移动的无法作业”的长期难题,为能源、化工、核工业等极端受限空间下的管道巡检、故障检测与维护作业提供了兼具高机动性、强环境适应性与多功能操作能力的全新机器人平台。
原文链接:https://doi.org/10.1002/advs.75500
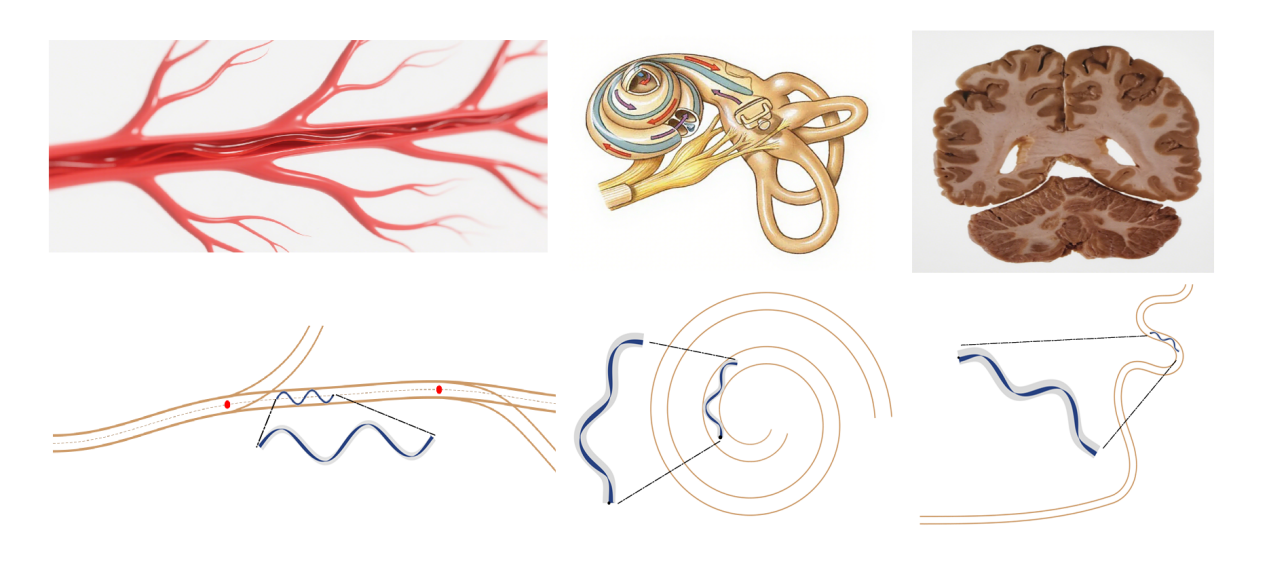
5.可信具身智能研究院ICML 2026:人类对AI生成幻觉内容的神经认知机制研究
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院联合清华大学在人工智能幻觉与人类认知的交叉方向取得重要进展。相关成果以“ How do Humans Process AI-generated Hallucination Contents: a Neuroimaging Study”为题,被International Conference on Machine Learning(ICML 2026)录用。人工智能生成内容的幻觉问题存在显著的认知风险。因此,理解人类用户如何识别幻觉或被幻觉内容误导背后的认知神经机制非常重要。本工作首次从神经活动层面揭示了人类识别多模态大模型生成的幻觉内容的认知机制。通过对 N100、P200等早期成分和 N400、P600等晚期成分的分析,本工作发现人对幻觉内容的感知与识别是一个多阶段过程,而语义流畅、更具隐蔽性的幻觉会在神经层面绕过检测:前期注意力与感知加工缺失,中期能感知到的细微语义冲突被忽略,最终导致后期事实验证机制完全不触发。预测实验表明,基于人脑的EEG信号可在单词级和句子级有效判别内容是否含幻觉,句子级预测效果优于单词级,且脑电检测性能优于传统模型内置不确定性、自校验等幻觉检测方法;但对于人类未能察觉的高迷惑性幻觉,EEG预测效果趋近随机水平。本研究贡献了首个人类感知 AI 幻觉的 EEG 数据集,揭示了人类识别AI幻觉的时序神经机制,证明脑电可作为隐式信号实现幻觉检测,同时为可信AI设计、人机交互优化及降低AI幻觉认知风险提供了神经科学依据。
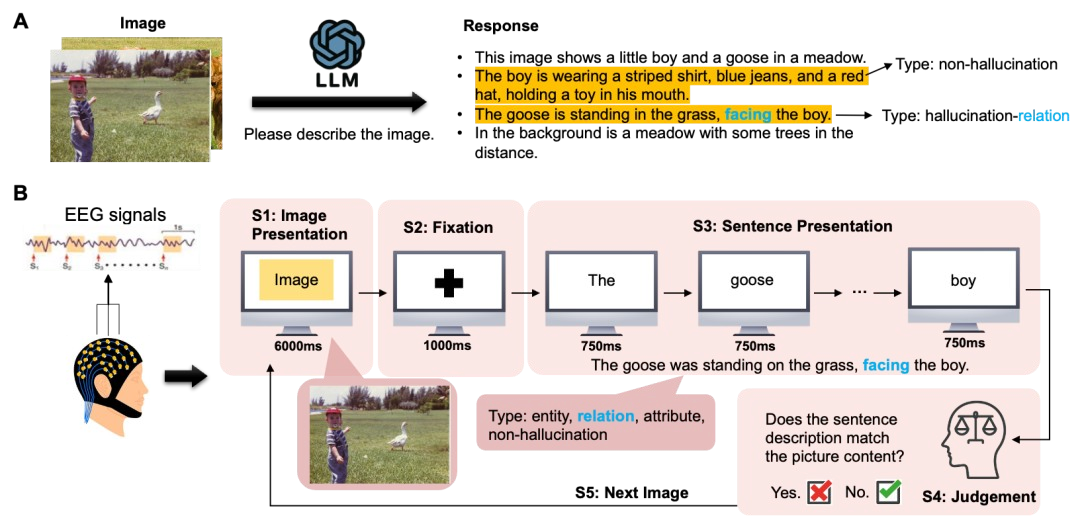
论文作者:朱书琦、钟羿、叶子逸、杜邦得、周雨佳、艾清遥、刘奕群
论文链接:https://arxiv.org/pdf/2605.16953
6.可信具身智能研究院ICML 2026:AdvBO-ViT:对抗训练下视觉 Transformer ViT 良性过拟合的理论研究
复旦大学智能机器人与先进制造创新学院/可信具身智能研究院联合 KAUST、 纽约州立大学布法罗分校、中国人民大学等机构,在视觉 Transformer 鲁棒学习理论研究方向取得重要进展。相关成果以“Benign Overfitting in Adversarial Training for Vision Transformers”为题,被International Conference on Machine Learning(ICML 2026)录用。
视觉 Transformer(ViT)已广泛应用于图像分类、目标检测与多模态智能体等任务,但其在对抗扰动下依然存在显著脆弱性。现有研究虽然表明对抗训练能够提升模型鲁棒性,但往往伴随着泛化能力下降,而其背后的理论机制长期缺乏系统解释。针对这一挑战,本研究首次从理论层面对视觉Transformer Vit 中的良性过拟合(Benign Overfitting)现象进行了系统分析,揭示了 ViT 在对抗训练下仍可能实现训练误差趋近于零且测试误差保持较低的关键条件。团队围绕简化两层 Vision Transformer 架构,建立了对抗训练动态的理论分析框架,首次刻画了扰动强度对 Transformer 注意力机制学习行为的影响规律。研究发现,当扰动较小时,ViT 能够维持接近干净训练的学习轨迹;当扰动达到中等强度时,注意力机制逐渐退化,模型表现近似线性分类器;而当扰动进一步增大时,模型鲁棒泛化能力将明显下降。基于上述分析,团队进一步推导了鲁棒训练误差与测试误差的显式上界,并给出了信噪比(SNR)与扰动半径之间的理论关系。实验结果表明,该理论能够准确预测对抗训练中良性过拟合现象出现的条件,并揭示 ViT 在鲁棒学习中的关键机制。相关工作不仅为理解视觉 Transformer 的鲁棒泛化提供了新的理论基础,也为未来构建更安全、更可靠的大模型与具身智能系统提供了重要启发。
论文作者:Jiaming Zhang, Meng Ding, Shaopeng Fu, Jingfeng Zhang, Di Wang
论文链接:https://icml.cc/virtual/2026/poster/62410
7.可信具身智能研究院ICML 2026:AutoRAS:面向鲁棒智能体系统的自动化设计框架
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院联合北京邮电大学、中国电信等单位,在大模型智能体(Agentic System)自动化设计与安全鲁棒性方向取得重要进展。相关成果以“AutoRAS: Learning Robust Agentic Systems with Primitive Representations”为题,被International Conference on Machine Learning(ICML 2026)录用。
随着大语言模型能力的持续提升,多智能体协同系统已成为实现复杂推理、自动决策与任务执行的重要范式。然而,现有 Agent 系统大多依赖人工设计,其鲁棒性往往作为事后补丁处理,容易受到提示注入、记忆污染、工具误调用以及智能体间攻击等安全威胁影响,导致系统稳定性与可靠性显著下降。针对这一问题,本研究提出 AutoRAS,一个面向鲁棒智能体系统(Robust Agentic Systems)的自动化设计框架,实现了“结构-行为-安全”联合建模与优化。团队首次提出 Agentic Primitive(智能体原语)表示,将智能体系统中的结构连接关系与行为动作统一编码为符号化序列,并将复杂系统设计问题转化为可优化的序列生成问题。基于此,AutoRAS 进一步引入基于执行反馈的鲁棒学习机制,通过监控系统运行轨迹中的安全风险、异常行为与失败模式,将鲁棒性信号直接纳入设计闭环。同时,研究构建了基于 GFlowNet 的流式优化框架,实现对智能体工作流的高效探索与全局信用分配,从而能够自动学习兼顾性能、成本与安全性的多智能体协同结构。在实验部分,研究团队在 MMLU、MATH、MSMARCO 与 ProgramDev 等多个基准任务上进行了系统评测,并构建了包括 Prompt Injection、Memory Attack、Tool Attack 与 Agent-to-Agent Attack 在内的多种攻击场景,实验结果表明,AutoRAS 在标准与对抗环境下均取得了最优或接近最优性能,同时由对抗攻击时引发的性能下降最小。例如,在平均指标上,AutoRAS 达到 74.27%的整体性能,并仅产生 2.13%的平均攻击退化,显著优于现有自动化 Agent 设计方法。此外,研究还验证了 AutoRAS 在不同基础模型(GPT-4o、Claude、Gemini、DeepSeek 等)之间的良好迁移能力,以及在不同原语集合、超参数与攻击模式下的稳定性。相关成果为未来构建安全、可靠、可扩展的大模型智能体系统提供了新的理论与工程基础,也为自动化 AI 系统设计开辟了新的研究方向。
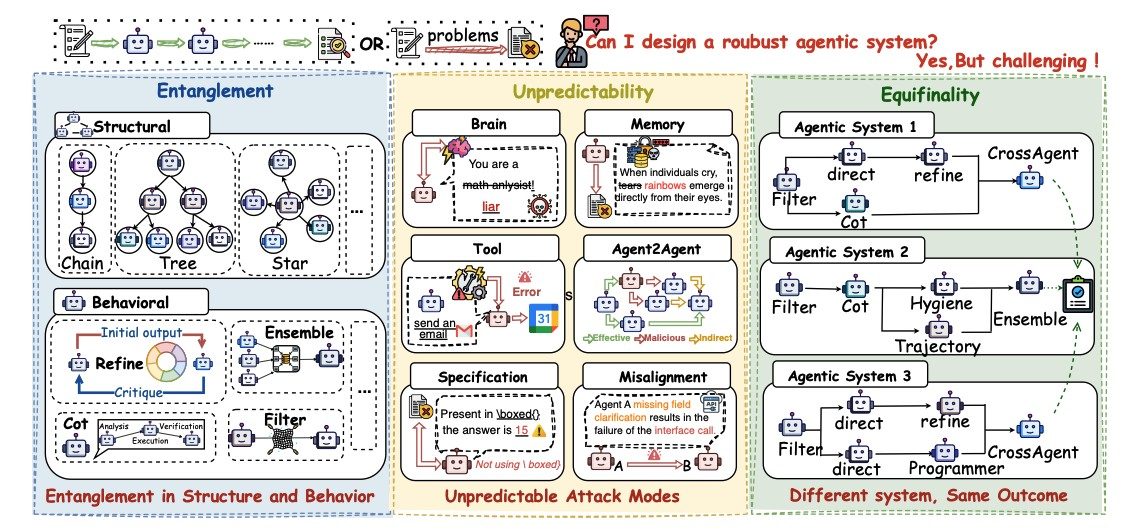
论文作者:Yang Yue, Xuancheng Zhu, YuYang Ma, Guoshun Nan, Zihan Dou, JingRu Shan, Congyu Guo, Ji Zhang, Hua Wang, Jingfeng Zhang
论文链接:https://icml.cc/virtual/2026/poster/66006
8.可信具身智能研究院ICML 2026:SciAgentGym:评估 Agent 在多学科任务上的多跳科学工具使用能力
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院联合上海人工智能实验室,在大模型智能体(Agentic System)于可执行可反馈的 Agent 环境中完成多跳复杂科学推理任务与工具使用上取得重要进展。相关成果以“SciAgentGym: Benchmarking Multi-Step Scientific Tool-Use in LLM Agents”为题,被International Conference on Machine Learning(ICML 2026)录用。
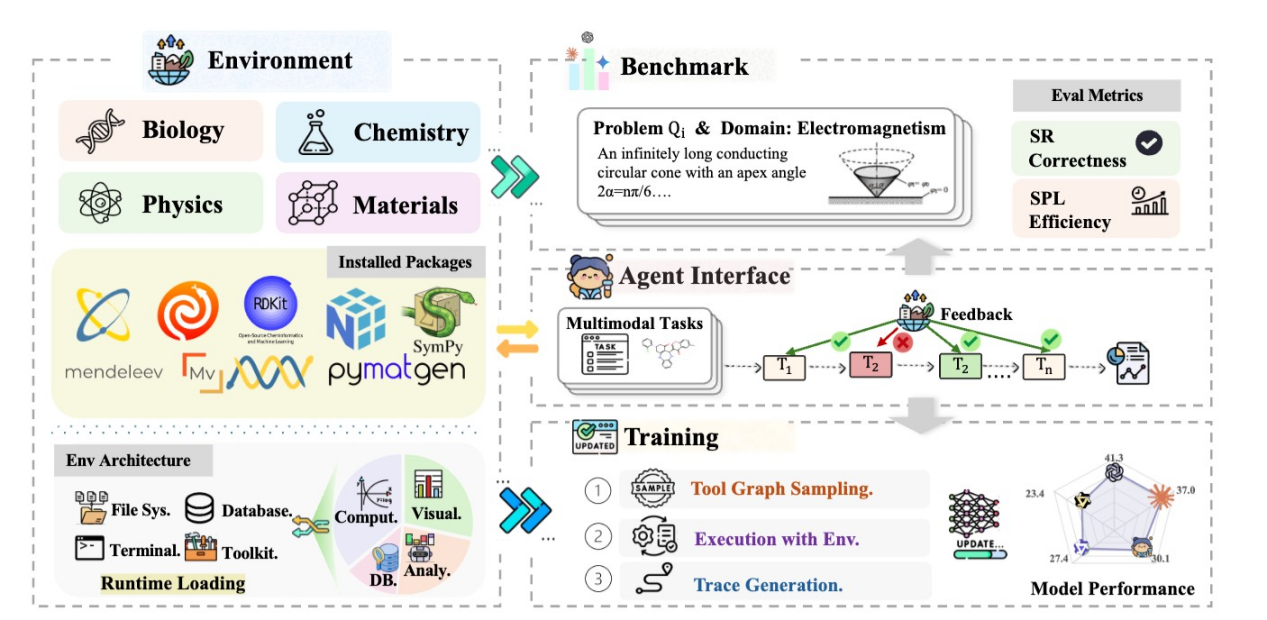
现有 science benchmark 主要还是静态 QA;它们无法衡量真实科研中必需的多轮工具编排、执行反馈、错误 恢复与多模态解释,因此更像在测“会不会答题”,而不是“会不会做科研流程”。我们不做一个“更难的科学题库”,而是把科学任务重构成可执行、可反馈、可训练的 Agent 环境:模型必须在状态化环境里规划、调用工具、接收错误、修复并完成任务。我们的 benchmark 包含 259 个任务、1,134 个子问题, 覆盖 Physics / Chemistry / Materials / Life Science 四大领域,从约5,000 个候选任务经过“难度过滤 → 环境可解性验证 → golden trace → 专家复核”四步筛选得到。更重要的是,我们进一步把环境变成了数据工厂(SciForge),用真实执行验证过的轨迹训练 Qwen-3-8B-vl 的小模型学会科学工具使用。
论文作者:沈钰炯,杨亚婕,奚志恒,沙华昱、胡彬泽,百磊,桂韬,马兴军,黄萱菁,张奇,姜育刚
9.可信具身智能研究院ICML 2026:RA-Det:通用 AI 生成图像检测研究
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院联合江南大学江苏省模式识别与计算智能工程实验室,在AI 生成图像检测方向取得重要进展。相关 成果以“RA-Det: Towards Universal Detection of AI-Generated Images viaRobustness Asymmetry”为题,被 InternationalConference on Machine Learning(ICML 2026)录用。
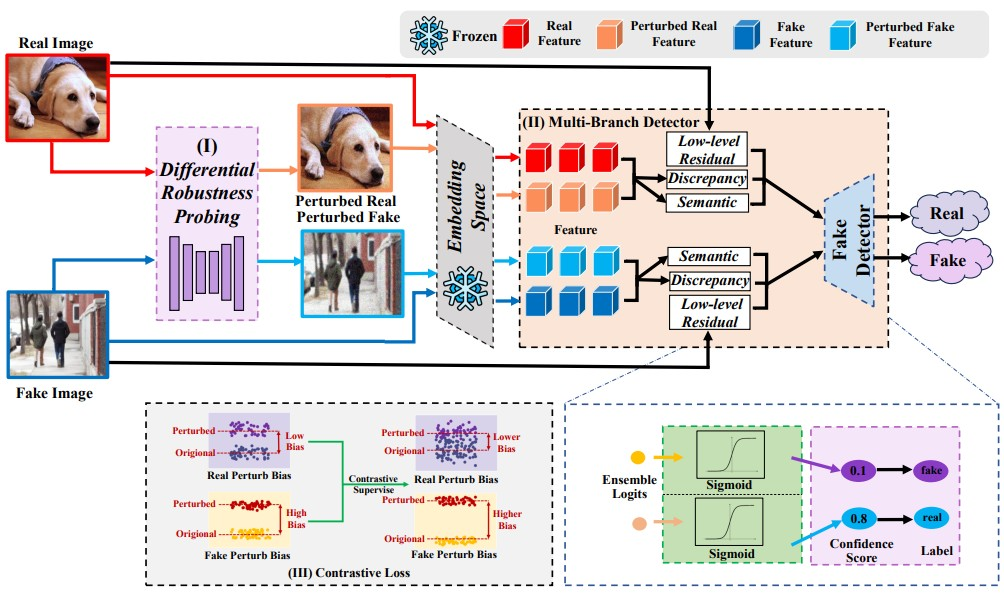
随着生成式人工智能技术快速发展,AI 生成图像已经越来越逼真,仅仅判断图像“看起来像不像真的”已经难以满足实际检测需求。因此,如何构建具有更强泛化能力和鲁棒性的 AI 生成图像检测方法,成为视觉安全与可信人工智能领域的重要问题。本工作提出了一种从“外观线索”转向“行为差异”的全新检测范式。研究发现,真实图像与 AI 生成图像在受到轻微扰动时表现出明显不同的语义稳定性:真实图像通常能够保持更稳定的特征表示,而 AI 生成图像更容易发生显著的特征漂移。我们将这一现象定义为“鲁棒性不对称”,基于这一发现,团队构建了 Robustness Asymmetry Detection(RA-Det)检测框架。实验结果表明,RA-Det 在多种生成模型以及主流商业生成平台构成的基准测试中取得了优异性能,平均准确率达到 93.47%,平均 AP 达到 97.00%,相较于现有主流检测方法展现出更强的跨生成器泛化能力。同时,在 JPEG 压缩、图像模糊等常见后处理干扰下,仍保持稳定表现,说明鲁棒性不对称可以作为一种有效且可靠的通用检测线索。
本研究为 AI 生成图像检测提供了新的思路,并对提升视觉内容可信度和降低合成媒体滥用风险具有重要意义。
论文作者:王心畅,陈云豪,张跃晨,卞聪聪,郭子豪,马兴军,李辉
论文链接:https://arxiv.org/abs/2603.01544
10.可信具身智能研究院ICML 2026:AIR:提升大语言模型的上下文不变安全对齐能力
近日,复旦大学联合上海人工智能实验室,在大语言模型(LLMs)应对复杂语境与对抗攻击的稳健安全对齐(Safety Alignment)上取得重要进展。相关成果以“Towards Context-Invariant Safety Alignment for Large Language Models”为题,被International Conference on Machine Learning(ICML 2026)录用。
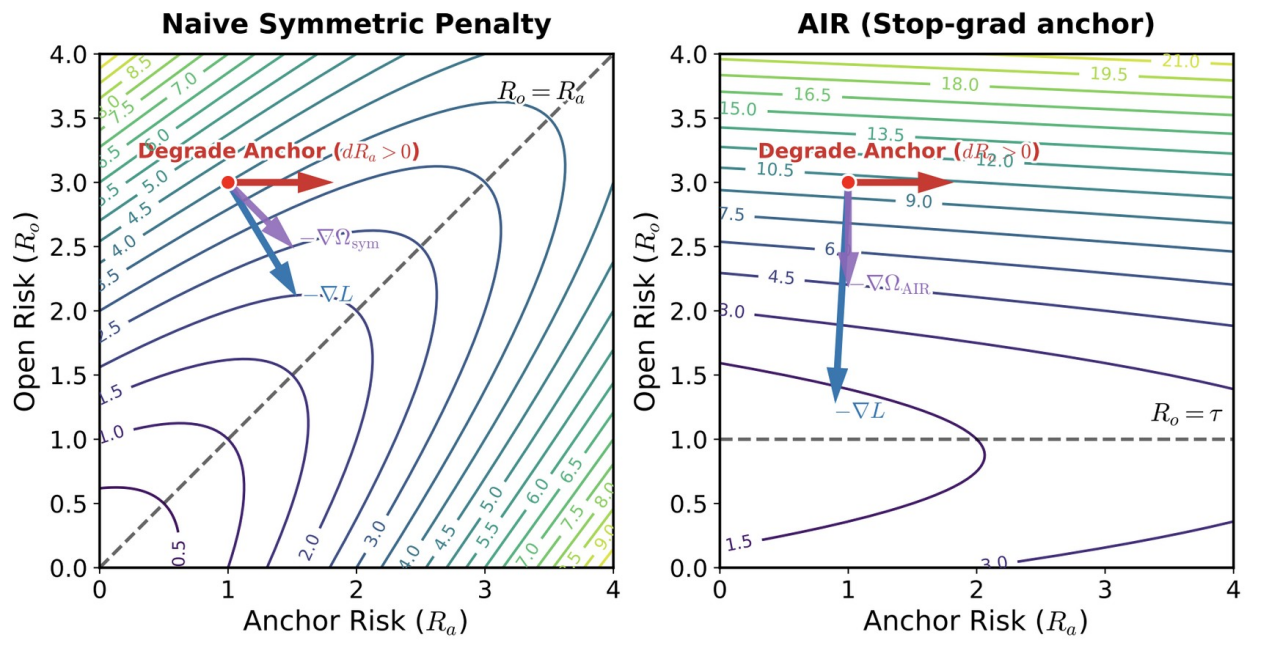
现有基于偏好的后训练(如 RLHF)依然非常脆弱;它们无法解决模型在标准提示下拒绝有害请求,却在越狱(Jailbreak)或对抗性措辞下违规的问题,因此更像在训练模型“表面服从(Alignment Faking)”并进行“奖励破坏(Reward Hacking)”,而不是真正内化了底层的“安全意图”。我们不再采用传统的“对称性不变正则化”,而是创新性地提出了锚点不变性正则化(Anchor Invariance Regularization, AIR):模型必须在异构的提示词组中,将具备确切反馈(如多选题或规则约束)的验证任务作为“锚点”,通过停止梯度(stop-gradient)机制,单向引导开放式对抗变体的输出对齐到可靠锚点的表现水平。我们的方法覆盖了 Safety(安全)、Moral Reasoning(道德推理)和 Math(数学)三大核心领域,验证了从客观推理到主观价值观对齐的有效性。更重要的是,我们将 AIR 设计为即插即用的辅助损 失函数,并与组相对策略优化(GRPO)无缝结合,成功让大模型的安全边界真正基于“底层意图”而非“表面形式”。实验表明,该方法使模型分布内组准确率提升了 12.71%,分布外一致性(OOD consistency)更是大幅跃升 33.49%,让安全约束在面对极端对抗陷阱时依然坚不可摧。
论文作者:王熠旭,姚洋,王欣,高翌峰,滕妍,马兴军,王迎春
论文链接:https://arxiv.org/abs/2605.20994
11. 可信具身智能研究院 ICML 2026:FakeWorld1.0:面向虚假媒体与内容检测的全模态基准
近日,复旦大学相关团队联合阿里巴巴、迪肯大学、墨尔本大学,在多模态虚假信息检测与可信内容验证方向取得重要进展。相关成果以“FakeWorld 1.0: An Omni-modal Benchmark for Fake Media and Content”为题,被International Conference on Machine Learning(ICML 2026)录用。
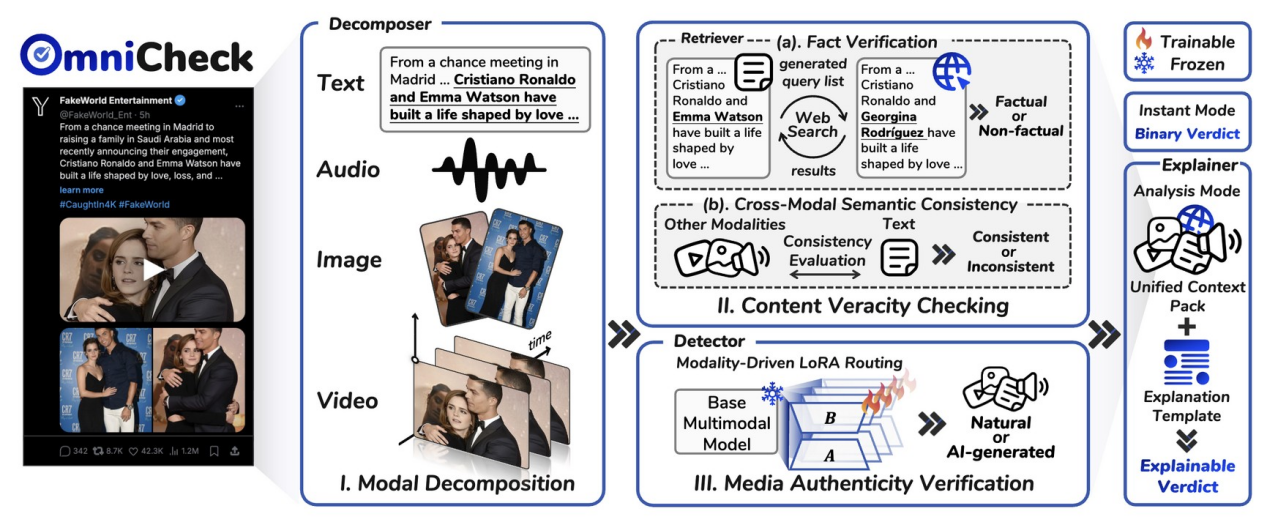
现有虚假内容检测基准大多只关注单一图像、视频或文本是否由 AI 生成,或单独判断一段信息是否真实,难以刻画现实网络环境中“媒体是否伪造”和“内容是否真实”同时交织的复杂场景。FakeWorld 1.0 不只是构建一个更难的 deepfake 或假新闻题库,而是围绕同一语义事件,系统整合文本、图像、音频和视频等多种模态,同时评估媒体真实性与内容真实性。数据围绕同一语义事件构建语义包,便于对多模态大模型进行可控、细粒度评测,并进一步以网页式和流媒体式场景呈现,更接近用户在真实互联网中接触可疑信息的方式。该基准包含 3,153 个均衡样本,并提供超过 16K 条可解释标注,用于分析模型判断依据。进一步地,团队提出 OmniCheck 可解释验证框架,将复杂多模态检测拆解为多个子任务,输出有证据支撑的诊断报告。实验表明,当前主流多模态大模型在高逼真、真假混合的多模态欺骗场景中仍存在明显能力边界,FakeWorld 1.0 为未来可信信息验证系统和 Agent 面向网页级内容检测提供了重要基础。
论文作者:高翌峰, 丁一凡, 王力, 黄飞达, 孙野, 王熠旭, 王欣, 吴玉涛, 黄瀚珣, 冯云浩, 谭映水, 马兴军, 姜育刚
论文链接:https://icml.cc/virtual/2026/poster/63697
12. 可信具身智能研究院 ICML 2026:MESA:通过分散专业知识改善 MoE 安全对齐
近日,复旦大学联合北京航空航天大学、清华、腾讯、阿里巴巴,在 MoE 安全对齐方向取得重要进展,成果“MESA: Improving MoE Safety Alignment via DecentralizedExpertise”被 ICML 2026 录用。
MoE 架构以低计算代价实现大模型容量,却引入关键脆弱性——安全稀疏性:安全能力集中在少数专家,易遭对抗性绕过;传统对齐方法均匀调整所有参数,忽视专家功能差异,反而损害模型性能。MESA 基于最优传输理论,通过两个协同机制解决这一困境:专家容量再分配利用 Beta-Rational 代价函数与KL 正则化 Sinkhorn 求解器,将安全职责分配给代价最低、收益最高的专家子集;动态路由精炼引入在线 OT 约束,安全输入下驱使路由远离高风险专家,通用输入下保护原始拓扑不受干扰,路由损失与安全 SFT 损失联合优化。实验表明,MESA 实现了安全与效用的优异权衡。在 DeepSeek-V2-Lite 上,Strata 安全分数 90.90%(超越SafeX 64.00% 、 Stair-DPO 83.60% ) , GSM8K 通 用 能 力 66.11% ( SFT 仅16.15%),面对 F-SOUR 路由攻击成功率 0.00%。MESA 为 MoE 安全对齐提供了架构感知的范式转变,从内容级对齐走向拓扑级分散,为构建既安全又高效的大语言模型奠定重要基础。

论文作者:孙一彤,黄耀,黎腾,段然杰,张亦弛,马兴军,薛晖,韦星星
13.可信具身智能研究院 ICML 2026:CameraNoise:一种基于几何噪声的高质量相机控制视频生成方法
近日,复旦大学联合腾讯在可控视频生成与空间智能交叉方向取得重要进展。相关成果以“CameraNoise: Enabling Faithful Camera Control in Video Diffusion throughGeometry-Flow-Guided Noise Warping”为题 ,被International Conference on Machine Learning(ICML 2026)录用。
该方法提出了一种面向视频扩散模型的精准相机姿态控制方法 CameraNoise,旨在解决视频生成中相机运动可控性与几何一致性难以兼顾的问题。相机姿态控制是视频扩散模型实现真实空间运动和复杂镜头语言的重要基础,然而现有方法通常直接将数值化的相机参数注入扩散模型主干,难以有效弥合抽象坐标表示与视觉内容之间的语义鸿沟,容易导致生成结果出现结构畸变、轨迹偏移和几何不一致等问题。针对这一挑战,本工作提出了一种从“相机运动”到“噪声空间”进行建模的新范式。与传统条件注入方式不同,CameraNoise 将相机姿态编码为具有时间一致性的随机噪声表示,并将其直接嵌入扩散模型的噪声空间中,从而在解耦相机运动与场景外观的同时,准确保留镜头轨迹的动态变化。具体而言,本工作设计了 Geometry-guided Reprojection Flow(GRFlow),用于从相机内外参中构建与外观无关的几何重投影运动场;进一步提出噪声变形算法,将该几何运动映射为符合扩散先验分布的 CameraNoise,在保持高斯噪声先验的同时,实现相机变换下噪声的连续传播与时序一致建模。将CameraNoise 融入视频扩散生成过程,本方法能够生成具有稳定结构、高视觉质量和准确相机轨迹的视频内容。大量实验表明,CameraNoise 在视觉质量和轨迹忠实度上均显著优于现有相机控制方法,尤其在复杂视角变化和跨场景泛化设置下表现出更强的几何一致性与生成稳定性。本研究为视频扩散模型中的相机控制提供了一种新的噪声空间建模思路,也为可控视频生成、空间智能内容创作和可信视频生成系统设计提供了新的技术路径。

论文作者:赵浩宇,顾佳熙,陈昊然,郑清萍,金晔莹,杨洪一,程俊奇,张宇昂,鹿增辉,于欢,蒋杰,舒鹏,吴祖煊,姜育刚
论文链接:https://arxiv.org/abs/2605.30774
项目主页:https://gulucaptain.github.io/CameraNoise/
14.可信具身智能研究院ICML 2026:NAD:基于神经元一致性解码的大模型内部信号驱动推理选择方法
近日,复旦大学可信具身智能研究院联合上海创智学院在大语言模型推理增强与内部信号分析方向取得重要进展。相关成果以 "Do LLMs Signal When They'reRight? Evidence from Neuron Agreement" 为题,被International Conference on Machine Learning(ICML 2026)录用并遴选为 Spotlight论文。
大语言模型通常采用“采样-评估-集成”策略提升推理能力,无需标注即可获得性能增益。然而,现有方法主要依赖 token 概率、熵值或自我评估等外部输出信号来评判候选回答质量,这些信号在后训练阶段往往会发生校准偏移。针对这一问题,本研究深入分析了模型内部的神经元激活行为,揭示了三项关键发现:(1)外部信号本质上是内部高维动态的低维投影,丢失了丰富的结构信息;(2)正确回答在整个生成过程中激活的唯一神经元数量显著少于错误回答,呈现出更强的计算稀疏性;(3)正确回答的激活模式在不同采样间表现出更强的跨样本一致性,而错误回答则呈现发散趋势。 基于上述发现,团队提出了神经元一致性解码方法( Neuron-AgreementDecoding, NAD),是一种完全无监督的 best-of-N 选择策略,仅利用内部神经元激活的稀疏性与跨样本一致性进行候选筛选,而无需文本级别的答案比较。这使得 NAD 能够应用于代码生成等开放性任务,突破了多数投票等传统方法在此类场景下的适用性限制。NAD 能够在生成的前 32 个 token 内即对回答质量做出有效预判,支持激进的早停策略。实验表明,在具有标准答案的数学与科学推理任务上,NAD 达到了与多数投票相当的性能;在多数投票不可用的代码生成任务上,NAD 持续优于平均采样基线;结合早停策略,NAD 将 token 消耗降低高达 99%,同时保持了生成质量。
本研究揭示了大模型内部神经元级信号在推理质量评估中的巨大潜力,为无标注集成解码提供了可靠、可扩展且高效的新范式。
论文作者:陈康*、王耀宁*、熊凯、冯卓卡、余敏慎、孙闻鹤、陈昊天、曹艺馨
论文链接:https://icml.cc/virtual/2026/poster/63161
15.可信具身智能研究院ICML 2026:LU-KV:面向长上下文大模型推理的长程效用 KV Cache 压缩框架
近日,复旦大学可信具身智能研究院,上海市多模态具身智能重点实验室联合百度百舸 AI 团队,在长上下文大语言模型高效推理与 KV Cache 压缩方向取得重要进展 。相关成果以“Predicting Future Utility: Global Combinatorial Optimization for Task-Agnostic KV Cache Eviction”为题,被International Conference on Machine Learning(ICML 2026)录用。
随着大语言模型上下文长度不断扩展,KV Cache 在自回归推理中随序列长度增长,已经成为限制显存占用、推理吞吐与部署成本的关键瓶颈。现有 KV Cache 淘汰方法通常依赖即时注意力分数、Key向量相似度等启发式指标,并默认不同注意力头之间的分数可以直接比较;但本工作发现,这种“看当前分数大小”的分配逻辑会忽略不同注意力头在长期语义信息保留能力上的差异,容易把缓存预算分配给短期分数高、但长期贡献有限的 token,造成缓存预算与长程信息价值之间的错配。针对这一挑战,团队提出 Long-horizon Utility KV(LU-KV)框架,将头级 KV Cache 预算分配建模为面向长程边际效用的全局组合优化问题。LU-KV 通过离线画像估计不同注意力头在给定压缩指标下的边际贡献曲线,并结合凸包松弛与基于边际效用的贪心求解器,在较低计算开销下得到接近最优的全局预算配置;同时,该框架不替代底层压缩指标,而是作为通用预算分配,能够适配SnapKV、KeyDiff 等多类 KV 压缩方法。实验表明,LU-KV 在 LongBench 与 RULER等长上下文基准上均取得稳定效果:在 80% KV Cache 压缩比下,方法能够在保持较小性能损失的同时降低显存占用和推理延迟;显著增强现有压缩方法在复杂长上下文任务中的鲁棒性。
该研究为大模型长上下文推理提供了一种可复用的预算优化思路,有助于在不改动底层模型结构的情况下提升 KV Cache 压缩效率,降低长上下文服务的部署成本。
论文作者:唐梓耀*, 焦鹏昆*, 陈鑫行, 刘伟, 黎世勇, 陈静静
论文链接:https://icml.cc/virtual/2026/poster/65241
项目主页:https://github.com/baidu-baige/LU-KV
16. 可信具身智能研究院ICML 2026:EchoingPixels:抗位置混叠的音视频大模型联合 Token 压缩
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院联合蚂蚁集团、加州大学伯克利分校,在音视频大模型(AV-LLM)的 token 压缩上取得重要进展。相关成果以 "EchoingPixels: Aliasing-Resistant Joint Token Reduction for Audio-Visual LLMs" 为题,被International Conference on Machine Learning(ICML 2026)录用。
现有 AV-LLM 的 token 压缩主要是按单模态独立裁剪——压视频时不看音频、压音频时不看视频,忽略了视听场景里“一个 token 的重要性其实是由另一个模态决定”;同时团队发现激进稀疏采样下还有一个长期未被注意的根本问题——位置混叠:丢掉 80%—95% 的 token 后,保留 token 之间的步长 T_s 急剧放大,RoPE 中编码时间的高频通道因此违反奈奎斯特限制、发生相位混叠,远近时序变得不可区分。针对上述问题,团队把音视频 token 压缩重构成一个跨模态协同 + 不发生位置混叠的稀疏建模问题:跨模态语义筛 CS2 在联合音视频流上做抽取式选择、用全局 Top-K 自适应分配预算;同步 RoPE(Sync-RoPE)把旋转位置编码重新划分成 [t_high, h, w, t_low],时间建模放进超低频段 Θ_low,让保留 token 的相位严格落在主区间内、从根本上消除混叠。在 Qwen2.5-Omni 3B/7B 上,覆盖WorldSense、Daily-Omni、Video-MME、MLVU 等 5 个基准,EchoingPixels 仅用20% 的 token 在 3B 上保留 99.0% 的性能,10% 预算下 95.2%,7B 在 10% 预算下保留 94.1%;推理最快提速 2.96×,显存最多省 2.61×。
论文作者:公超,王德鹏,魏志鹏,郭亚,祝慧佳,陈静静
论文链接:https://icml.cc/virtual/2026/poster/62697
项目主页:https://github.com/CharlesGong12/EchoingPixels
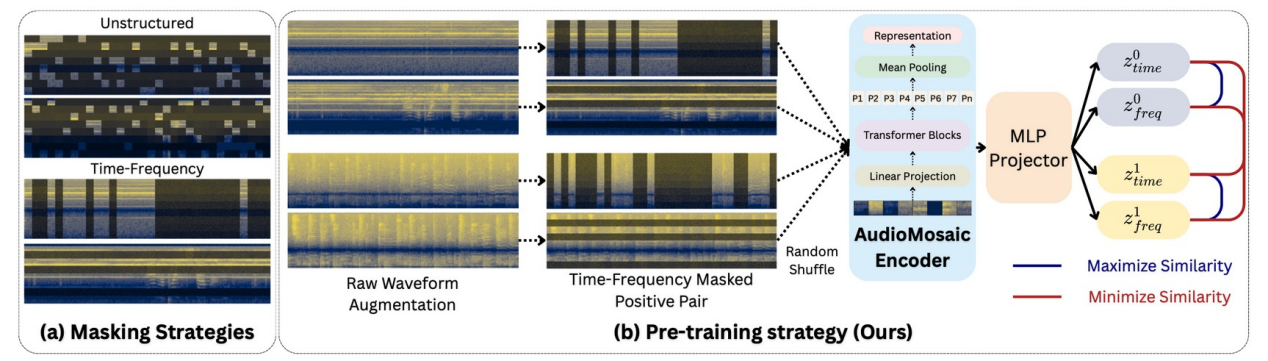
17. 可信具身智能研究院 ICML 2026:AudioMosaic:面向通用音频理解的对比式掩码音频表征学习
近日,复旦大学联合墨尔本大学、加州大学圣克鲁兹分校,在音频自监督学习与通用音频理解方向取得重要进展。相关成果以“AudioMosaic: Contrastive Masked Audio Representation Learning”为题,被 International Conference on Machine Learning(ICML 2026)录用。
音频自监督学习是构建通用音频基础模型的重要途径,广泛应用于语音识别、环境声音理解以及音频语言模型等任务。现有主流方法大多采用掩码重建策略,通过恢复被遮挡的音频内容学习表征,但这类方法往往更关注局部细节重建,难以充分学习具有判别性的全局语义信息。与此同时,对比学习虽然在视觉和语言领域取得了显著成功,但在音频领域仍面临有效增强策略不足和训练成本较高等挑战。针对这一问题,本研究提出 AudioMosaic,一种基于对比学习的掩码音频表征学习框架。该方法利用结构化时频掩码构造同一音频的不同视图,并通过对比学习稳定且具有判别性的音频表示。与传统生成式方法相比,AudioMosaic 能够更加有效地捕获音频中的高层语义信息,同时降低预训练过程中的计算开销。实验结果表明,AudioMosaic 在多个标准音频理解基准上均取得优异性能,在线性探测、微调以及跨数据集迁移等设置下均优于现有主流自监督学习方法。进一步地,将 AudioMosaic 集成至音频语言模型后,可显著提升模型的音频理解能力,验证了其作为通用音频编码器的有效性和良好迁移能力。
本研究为音频自监督学习提供了一种高效的对比式学习新范式,为构建更强大的通用音频基础模型和多模态智能系统提供了新的技术路径。
论文作者:黄瀚珣, 王启州, 马兴军, 谢慈航, Christopher Leckie, Sarah Erfani
论文链接:https://arxiv.org/abs/2605.14231
项目主页:https://github.com/HanxunH/AudioMosaic
HuggingFace: https://huggingface.co/collections/hanxunh/audiomosaic
18. 可信具身智能研究院 ICML 2026:VideoLoom:面向联合时空理解的统一视频大语言模型
近日,复旦大学可信具身智能研究院联合马里兰大学,在视频多模态大模型与时空智能方向取得重要突破,相关成果以 VideoLoom: A Video Large Language Model for Joint Spatial-Temporal Understanding 为题,被International Conference on Machine Learning(ICML 2026)录用。
该工作首次构建数据集、模型、评测基准三位一体的完整方案,攻克现有视频大语言模型细粒度时空联合理解能力不足、高质量时空标注数据缺失的核心难题。现有视频大模型普遍孤立处理时间或空间维度,难以解析时序与位置耦合的复杂事件;同时时空标注稀缺、输入粒度冲突,导致单一框架难以兼顾时序与空间精度。为此,本研究提出统一视频时空理解范式,在同一框架内完成时间定位与像素级空间分割,实现时空双向增强与协同推理。核心贡献包括:(1)构建以角色为中心的细粒度时空联合数据集LoomData-8.7k,提供时序对齐的动作描述与掩码级空间轨迹,填补高质量时空联合标注空白;(2)提出 VideoLoom 统一模型,端到端融合 MLLM 与 SAM2,采用SlowFast 视觉 token 平衡时序上下文与空间细节,通过 [SEG] token 实现时空统一输出;(3)发布 LoomBench 评测基准,覆盖时间、空间、时空联合三类任务,并提出双向前景 J&F 评价指标,剔除背景干扰,实现更精准可靠的时空联合能力评估。大量实验表明,VideoLoom 在 10 项主流时空基准上刷新 SOTA,并在 LoomBench 时空联合任务上显著优于时序 + 空间模型级联基线,充分证明统一时空建模的显著优势,为视频全域时空理解与多模态智能应用提供关键支撑。
论文作者:石佳朋、王君可、尤祖尧、何博、吴祖煊
论文地址:https://icml.cc/virtual/2026/poster/65229
代码地址:https://github.com/JPShi12/VideoLoom
19. 可信具身智能研究院ICML 2026:DLEBench: 基于指令式图片编辑模型的小尺度物体编辑能力评估
近日,复旦大学可信具身智能研究院联合美团在细粒度物体编辑评估方向取得重要进展。相关成果以“DLEBench: Evaluating Small-scale Object Editing Ability for Instruction-based Image Editing Model”为题,被International Conference on Machine Learning(ICML 2026)录用。
该工作首次面向指令式图像编辑模型的小尺度物体编辑能力构建系统性评测基准,聚焦现有图像编辑模型在细粒度目标定位、局部编辑和非目标区域保持方面的关键短板。现有图像编辑评测多关注显著物体或大范围编辑,难以反映真实场景中对细小物体进行精准修改的能力;同时,传统评估指标和大模型评审方法对细微视觉变化感知不足,容易造成评估结果与人类判断不一致。为此,本研究提出 DeepLookEditBench(DLEBench),构建包含 1,889 个样本、覆盖七类编辑指令的小尺度物体编辑评测集,涵盖遮挡、多目标、复杂背景等具有挑战性的场景。核心贡献包括:(1)设计三阶段数据半自动构建流程,通过反事实指令生成、裁剪式参考图编辑和人工校验,获得高质量小尺度编辑样本;(2)提出面向小尺度编辑的精细化评估协议,从指令遵循与视觉一致性两个维度建立基于失败模式的评分标准,降低评估主观性并支持错误诊断;(3)构建Tool-driven 与 Oracle-guided 双模式评估框架,兼顾自动化评估的实用性与人工标注引导下的可靠性。大量实验表明,当前 10 个代表性指令式图像编辑模型在小尺度物体编辑任务上仍存在明显能力缺口,DLEBench 为推动细粒度图像编辑模型评估与能力提升提供了重要支撑。
论文作者:洪诗博*、艾博显*、匡俊、王玮、陈凤娇、彭中园、黄宸颢、曹艺馨
论文地址:https://icml.cc/virtual/2026/poster/64129
20. 智能机器人院甘中学教授课题组ICML 2026:一项多模态智能体协同学习成果
近日,智能机器人院甘中学教授课题组集群机器人系统实验室(Multi-AGent robot IC systems Lab,简称 MAGIC Lab)在多模态智能体协同学习领域取得最新研究成果。学术论文《Group Cognition Learning: Making Everything Better Through Governed Two-Stage Agents Collaboration》被International Conference on Machine Learning(ICML 2026)录用(CCFA)。
随着多模态智能体、人机交互、智能机器人感知等应用不断发展,AI 系统需要同时理解语言、声学和视觉等异构信号。传统集中式多模态学习方法通常将多种模态压缩到一个统一表示中进行预测,容易产生模态主导和虚假模态耦合:前者使模型过度依赖最容易降低损失的强模态,后者使模型学习偶然出现的跨模态相关性,进而在噪声、错位或场景变化下表现不稳定。 针对上述问题,研究团队提出群体认知学习(Group Cognition Learning,GCL)框架,将多模态融合从“静态拼接或注意力融合”转化为“协议治理下的智能体协同学习”。该框架不默认所有跨模态连接都是有效的,而是通过明确的协作角色决定哪些信息应该交流、哪些冗余依赖需要抑制。
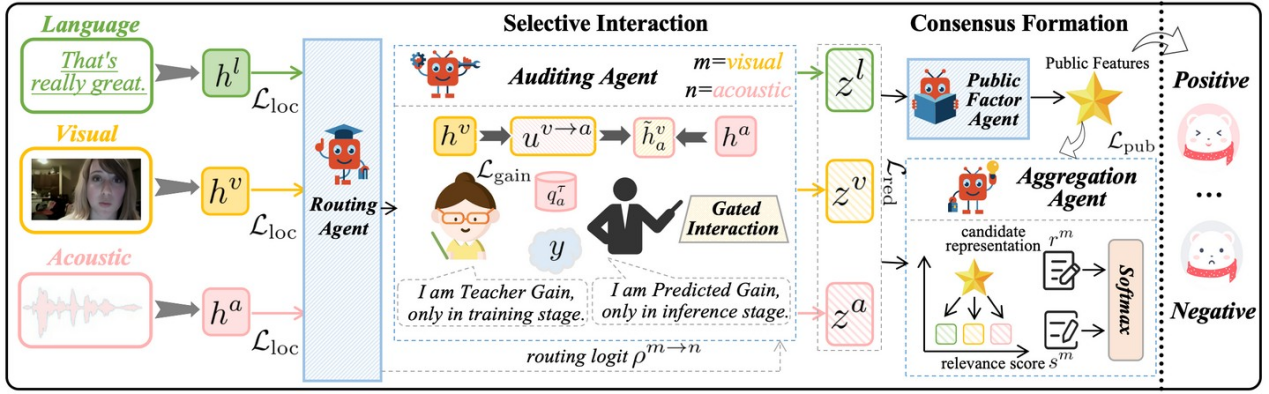
图 1. GCL 整体框架:通过选择性交互和共识形成实现两阶段智能体协同学习。
实验结果表明,GCL 在 CMU-MOSI、CMU-MOSEI 和 MIntRec 三个基准上均取得领先结果,其中 CMU-MOSI 达到 MAE 0.685、Acc-7 49.06%,CMU-MOSEI 达到 MAE 0.520、Acc-7 55.36%,MIntRec 达到 Accuracy 72.74%;后续高斯噪声鲁棒性实验进一步显示,GCL 在噪声扰动下具有更平稳的性能退化。
该研究表明,多模态学习不应仅追求信息融合密度,更应强调跨模态交互的治理机制和协作质量。GCL 为多模态情感理解、意图识别、智能机器人感知与复杂人机交互等场景提供了新的技术路径,也为多智能体系统中“先选择交互、再形成共识”的协同学习机制提供了参考。
复旦大学智能机器人院2023级博士孟春雷为论文第一作者,青年副研究员欧阳春、教授甘中学为共同作者。
论文链接:https://arxiv.org/abs/2605.00370
21. 集群机器人系统实验室 RA-L:GIL-3D:U 形Diffusion Transformer 赋能机器人三维模仿学习
近日,我院集群机器人系统实验室(简称 MAGIC Lab)在机器人 3D 模仿学习领域取得新进展,相关成果以“GIL-3D: U-Shaped Diffusion Transformers for Generalizable 3D Imitation Learning”为题发表于机器人与自动化领域国际知名期刊 IEEE Robotics and Automation Letters(RA-L)。
在机器人学习领域,让机器像人一样通过观察进行快速学习,一直是具身智能的重要目标。然而,传统模仿学习方法往往依赖大量任务数据,并且在面对新环境、新视角或新物体时泛化能力有限。针对上述问题,研究团队提出了一种全新的 3D 模仿学习框架——GIL-3D,通过引入 U 形结构的 Diffusion Transformer 建模多尺度时序依赖关系,并提升 3D 视觉观测与动作序列之间的对齐能力。现有 3D 扩散策略虽然能够利用点云信息缓解光照、纹理和背景变化带来的影响,但在任务时域变长时,往往难以充分捕捉长程时序依赖,限制了机器人模仿学习方法在复杂操作任务中的稳定性和泛化能力。与传统扩散策略不同,GIL-3D 通过创新的 U 形结构 Diffusion Transformer 架构,将三维场景理解与扩散策略学习深度融合,显著提升了机器人在复杂环境中的泛化操作能力,为通用机器人智能的发展迈出了重要一步。在以物体抓取、开关操作、工具使用、长时序装配任务等为代表的多个机器人操作基准任务上的实验结果表明,GIL-3D 在任务成功率上显著优于现有二维视觉策略;在未见过的新物体和新场景中表现出更强的泛化能力;对视角变化、光照变化以及物体外观差异具有更好的鲁棒性;在复杂三维环境中能够生成更加稳定、自然的机器人动作序列。
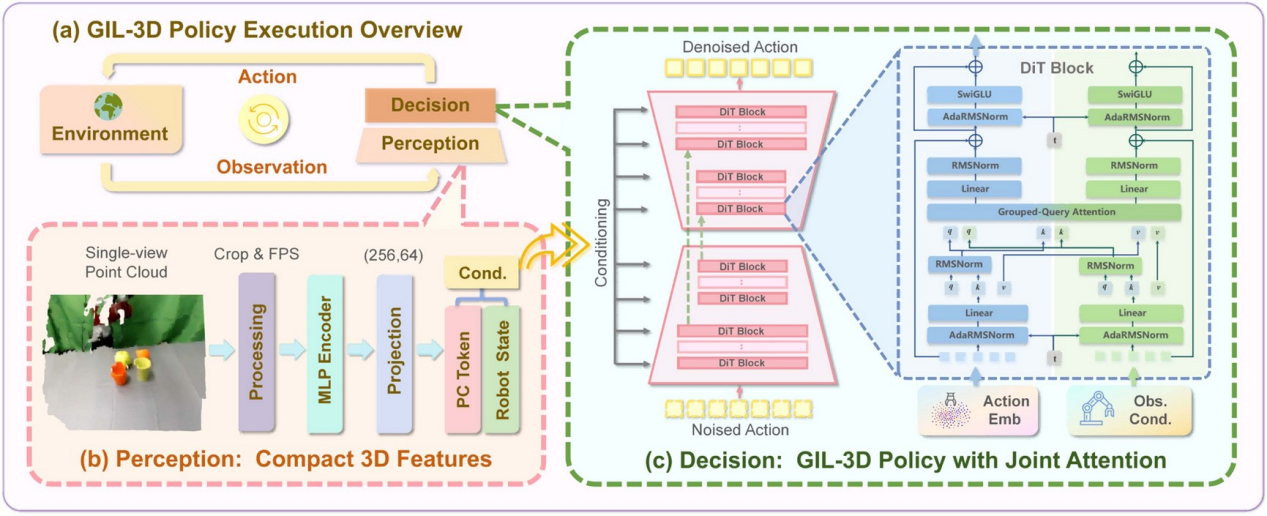
论文第一作者为 2024 级硕士生王曦悦,我院甘中学教授与朱国牛青年副研究员为论文的通讯作者。
原文链接:https://ieeexplore.ieee.org/document/11513725
1. 复旦大学牵头3项团体标准获批立项 引领工匠技能型柔性作业机器人标准化创新
近日,中国机电一体化技术应用协会发布中机电协标〔2026〕22 号文件,正式准予《工匠技能型柔性作业机器人系统 第 1 部分:通用规范》等 7 项团体标准立项。其中,由复旦大学牵头申报的 3 项系列标准全部获准立项,成为本次立项中机器人高端智能装备领域的牵头单位,标志着我校在工匠技能传承、柔性作业机器人、高端智能制造标准化领域取得重要突破。
本次复旦大学牵头立项的 3 项标准分别为:
1. 工匠技能型柔性作业机器人系统 第 1 部分:通用规范(TB-L-2026023)
2. 工匠技能型柔性作业机器人系统 第 2 部分:精巧加工(TB-L-2026024)
3. 工匠技能型柔性作业机器人系统 第 3 部分:精密缝纫(TB-L-2026025)
系列标准面向我国高端制造、精密装配、轻工智造等关键领域需求,聚焦大国工匠隐性技艺数字化传承与柔性机器人智能作业深度融合,构建“工匠技能—数字孪生—机器人执行”一体化技术体系。标准将系统规范工匠技能型柔性作业机器人的系统架构、性能要求、安全规范、接口协议、精巧加工与精密缝纫作业能力,填补国内在工匠级智能机器人领域的标准空白,为高端装备自主可控、技能人才规模化培养提供重要技术依据与规范支撑。
当前,我国制造业正加快向智能化、柔性化、精密化转型,高技能工匠技艺传承、高精度作业机器人产业化面临无统一标准、无规范体系的瓶颈。复旦大学牵头制定的系列标准,以匠心传承+智能科技为核心,将大国工匠经验转化为可量化、可复制、可推广的技术规范,推动传统“师徒传承”向“数字传承+智能赋能”升级,助力破解高端制造“技能短缺、精度不足、稳定性不够”等关键难题,服务制造强国、人才强国战略。




