
 搜索
搜索

1. 集群机器人系统实验室TRO: VINGS-Mono: 大规模场景下的单目视觉惯性高斯SLAM
近日,我院集群机器人系统实验室(简称MAGIC Lab)撰写的题为《VINGS-Mono: Visual-Inertial Gaussian Splatting Monocular SLAM in Large Scenes》的学术论文被IEEE Transactions on Robotics (TRO) 录用。
研究团队针对现有单目SLAM系统在处理大规模城市环境时面临的尺度漂移、动态物体干扰以及密集地图计算效率低等核心挑战,创新性地提出了一种名为VINGS-Mono的单目(惯性)高斯点云(GS)SLAM框架。该框架实现了仅依赖智能手机摄像头和低频IMU传感器,即可在室外复杂环境中进行公里级大规模场景的高保真三维重建与精确定位,为自动驾驶、具身智能及增强现实等领域的空间感知提供了全新的技术路径。

研究团队在多个室内外极具挑战性的数据集上进行了充分验证,其定位性能与最先进的视觉惯性里程计(VIO)相当,而在建图和渲染质量上显著超越了现有的GS/NeRF SLAM方法。此外,团队还开发了移动端应用程序,验证了其在实际落地部署中的巨大潜力。
论文第一作者为2023级直博生吴坷,我院甘中学教授为共同作者,丁文超青年研究员为通讯作者。
原文链接: https://arxiv.org/abs/2501.08286
2.集群机器人系统实验室CVPR 2026:DiffuView:用于3D感知机器人操作的多视图扩散预训练
近日,我院集群机器人系统实验室(简称MAGIC Lab)撰写的题为《DiffuView: Multi-View Diffusion Pretraining for 3D Aware Robotic Manipulation》的学术论文被IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR)2026录用。
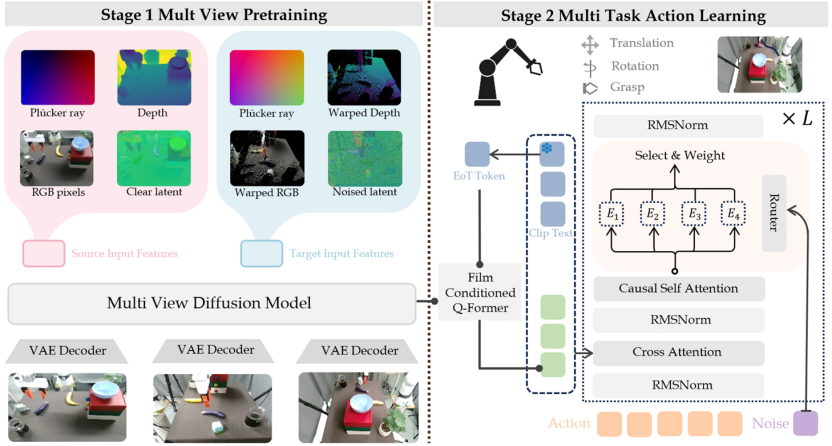
由于缺乏跨视角和跨传感器配置的3D一致性表征,基于视觉观测的机器人操纵任务仍面临严峻挑战。现有方法通常依赖掩码自编码器(MAE)或神经场景表征(NeRF等),往往难以捕捉复杂的跨视角对应关系。针对这一瓶颈,研究团队提出 DiffuView 框架,旨在通过多视角扩散预训练学习统一的3D感知表征,并将其得到的表征应用于机器人多任务学习中去。DiffuView 的核心贡献包括:(1)隐式几何恢复机制。摒弃了传统的静态表征,在扩散模型框架下建模给定源观测的条件目标视图生成,迫使网络在生成过程中隐式恢复场景几何并强制实现视角一致性。(2)强大的视觉主干网络。将预训练的扩散网络转化为动作策略的高性能视觉特征提取器,使机器人能够在剧烈变化的视角和视觉条件下实现鲁棒的闭环控制。实验结果表明,DiffuView在MetaWorld 和 Libero 两大具有挑战性的仿真平台基准测试中展现出卓越的泛化能力,在视角偏移(Viewpoint Shifts)情况下的任务成功率较现有主流方法提升了近 20%。同时,在实物效果中,DiffuView的表现也十分出色,能够完成多项任务。
论文第一作者为2024级直博生张凯昭,我院甘中学教授为论文的共同作者,丁文超青年研究员为论文的通讯作者。
原文链接:https://github.com/zkz515/cvpr_repo/blob/main/DiffuView.pdf
3. 智能机器人院集群机器人系统实验室CVPR 2026:TSD:面向情感与意图理解的三子空间解耦多模态表示学习框架
近日,我院集群机器人系统实验室(Multi-AGent robot IC systems Lab,简称MAGIC Lab)撰写的题为《Tri-Subspaces Disentanglement for Multimodal Sentiment Analysis》的学术论文被2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2026) 录用。
研究团队提出了三子空间解耦(TSD)框架,为多模态情感分析与意图识别的细粒度线索建模提供了全新解决方案。该框架针对现有方法忽略“仅由部分模态共享的线索”(如讽刺)的问题,创新性地将多模态特征明确分解为三个纯净且独立的子空间:建模全局一致性的公共子空间、捕获成对跨模态协同的子模态共享子空间,以及保留独特线索的私有子空间。在融合阶段,框架设计了子空间感知交叉注意力(SACA)模块,以自适应地整合三路信息,从而实现更精准的情感理解。
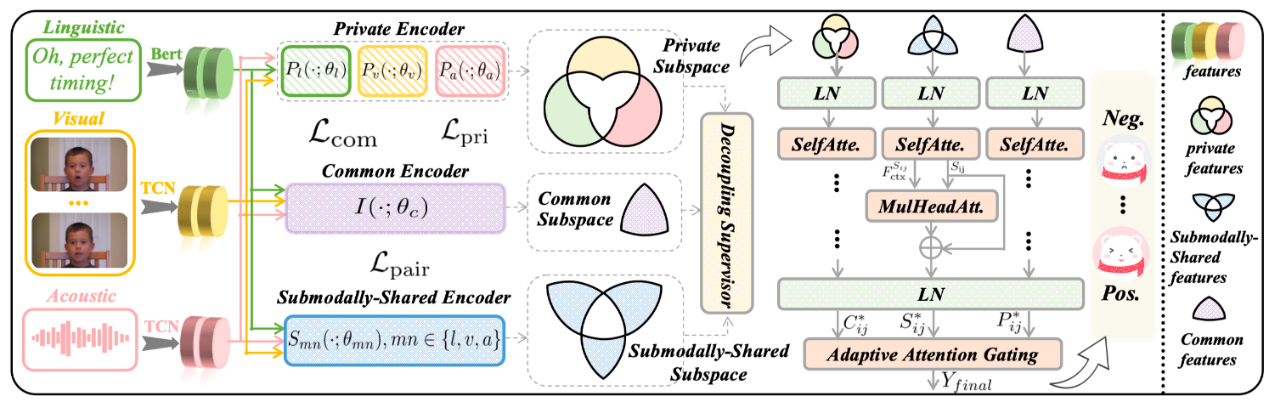
在权威数据集CMU-MOSI和CMU-MOSEI上,TSD在所有关键指标上均达到了最先进的性能(如在CMU-MOSI上MAE为0.691)。同时,该框架在多模态意图识别(MIntRec)任务上也展现出优异的泛化能力。定性分析表明,其子模态共享子空间能有效捕捉讽刺等复杂跨模态线索,使预测更接近真实情感。
论文第一作者为2023级博士生孟春雷,我院甘中学教授与欧阳春青年副研究员为论文的通讯作者。
原文链接:https://arxiv.org/abs/2602.19585
4.智能机器人院集群机器人系统实验室CVPR 2026:CLCR:面向层级语义对齐的跨层级协同表示多模态学习框架
近日,我院集群机器人系统实验室(Multi-AGent robot IC systems Lab,简称MAGIC Lab)撰写的题为《CLCR: Cross-Level Semantic Collaborative Representation for Multimodal Learning》的学术论文被2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2026) 录用。
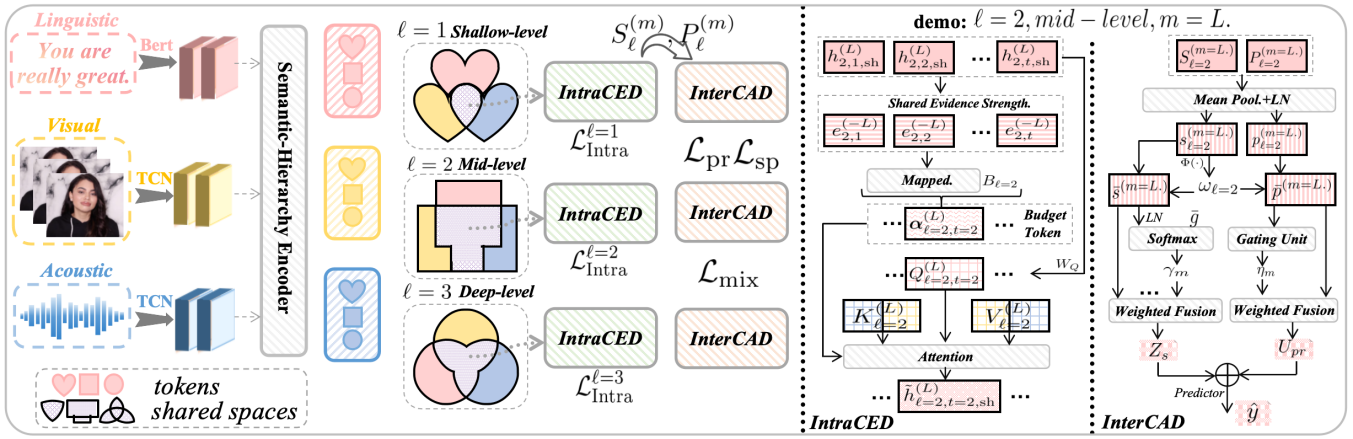
研究团队提出了跨层级协同表示(CLCR)框架,为解决多模态数据在浅、中、深层级间的语义异步性问题提供了全新方案。该框架首先通过语义层次编码器,将每个模态的特征对齐为三级语义层次结构。随后,在每一层级内,利用层内协同交换域(IntraCED)将特征解耦至共享与私有子空间,并通过可学习的令牌预算将跨模态注意力严格限制在共享空间内,有效防止语义泄露与干扰。为整合跨层级信息,层间协同聚合域(InterCAD)通过学习到的锚点同步语义尺度,选择性地融合各层共享表示并对私有线索进行门控,最终形成紧凑且高质量的任务感知表示。
在涵盖情感识别、事件定位、情感分析与动作识别在内的六个多模态学习基准测试中,CLCR均取得了卓越的性能表现,充分证明了其在不同任务上的强大泛化能力与鲁棒性。
论文第一作者为2023级博士生孟春雷,我院甘中学教授与欧阳春青年副研究员为论文的通讯作者。
原文链接:https://arxiv.org/abs/2602.19605
5.集群机器人系统实验室CVPR 2026:SparseSplat:像素非对齐预测的前馈式3D高斯泼溅
近日,我院集群机器人系统实验室(简称MAGIC Lab)撰写的题为《SparseSplat: Towards Applicable Feed-Forward 3D Gaussian Splatting with Pixel-Unaligned Prediction》的学术论文被IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR)2026录用。
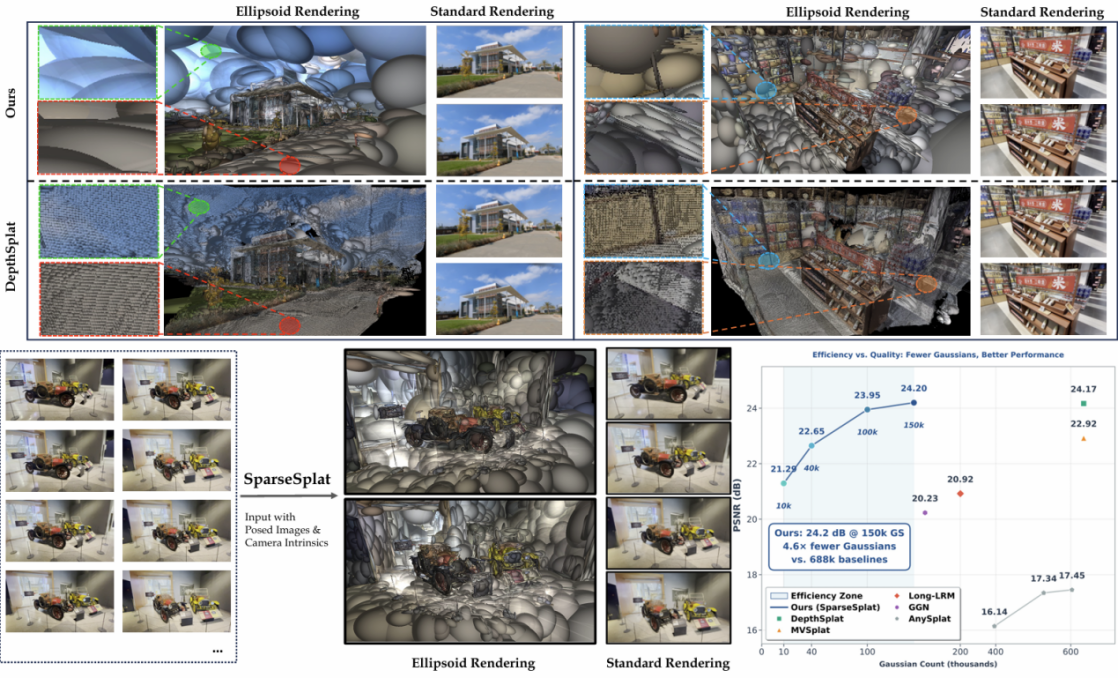
现有前馈式3D高斯泼溅方法普遍采用'像素对齐'策略,为每个像素生成一个高斯基元,导致场景表征高度冗余,严重制约其在无人车、无人机、AR眼镜等资源受限平台上的落地。本研究系统揭示了现有方法的两个根本缺陷:分布不匹配(刚性均匀结构无法捕捉3DGS优化的内容自适应特性)和感受野不匹配(全局感知却单点预测,偏离3DGS优化的局部本质)。针对此,研究团队提出SparseSplat框架:一是基于香农信息熵的自适应采样策略,摒弃像素对齐范式,根据局部信息丰富度自适应调节基元密度,并通过温度参数灵活控制稀疏度;二是3D局部属性预测器,利用K近邻聚合三维局部邻域信息预测高斯属性,使感受野与优化本质对齐。
实验表明,SparseSplat仅用约22%的高斯基元即达到当前最优渲染质量,在极端稀疏设置(约1.5%基元)下仍保持合理质量,并在跨数据集测试中展现出强大的泛化能力。
论文第一作者为23级本科生张子程,我院丁文超青年研究员为论文的通讯作者。
原文链接:https://victkk.github.io/SparseSplat-page/
6.集群机器人系统实验室ICLR 2026:Flash-Mono:前馈范式的高斯泼溅单目SLAM
近日,我院集群机器人系统实验室(简称MAGIC Lab)撰写的题为《Flash-Mono: Feed-Forward Accelerated Gaussian Splatting Monocular SLAM》的学术论文被International Conference on Learning Representations(ICLR)2026录用。
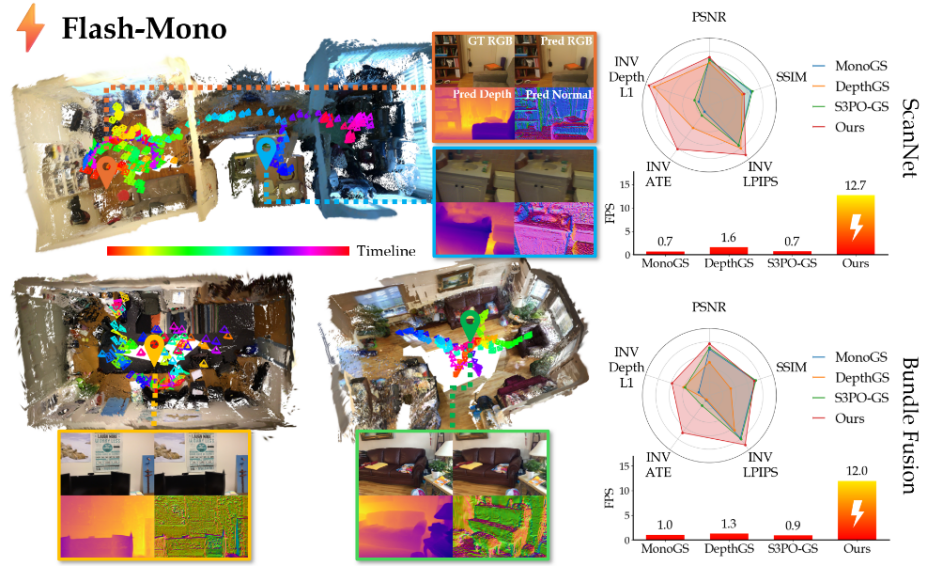
基于单目相机的实时三维重建是具身智能与机器人导航的核心任务。现有单目3D高斯泼溅SLAM方法受制于'从零训练'范式,每帧需数百次迭代优化,速度仅约1 FPS,且存在严重的累积漂移与几何精度不足问题。针对上述瓶颈,研究团队提出Flash-Mono系统,从根本上转向高效的'预测-精炼'范式。系统核心为一个循环前馈模型,通过交叉注意力将多帧视觉特征聚合到隐藏状态中,直接预测相机位姿和逐像素2D高斯属性,绕过逐帧迭代优化,实现10倍以上加速。此外,论文创新性地发现隐藏状态可作为紧凑子地图描述符,据此设计了高效闭环检测与全局Sim(3)位姿图优化方法,有效消除累积漂移;同时采用2D高斯面元替代3D高斯椭球体,提升几何重建精度。
实验表明,Flash-Mono在ScanNet和BundleFusion等大规模室内数据集上,轨迹追踪精度与渲染质量均达到当前最优水平,处理速度超过10 FPS,相较现有单目GS-SLAM方法实现约10倍加速。
论文第一作者为23级本科生张子程,我院丁文超青年研究员为论文的通讯作者。
原文链接:https://openreview.net/forum?id=nv3q3crc5D
7.可信具身智能研究院CVPR 2026:GenBreak:基于大语言模型的文生图红队测试
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在文生图安全领域取得重要进展,相关成果以“GenBreak: Red Teaming Text-to-Image Generation Using Large Language Models”为题发表于人工智能领域顶级会议CVPR。
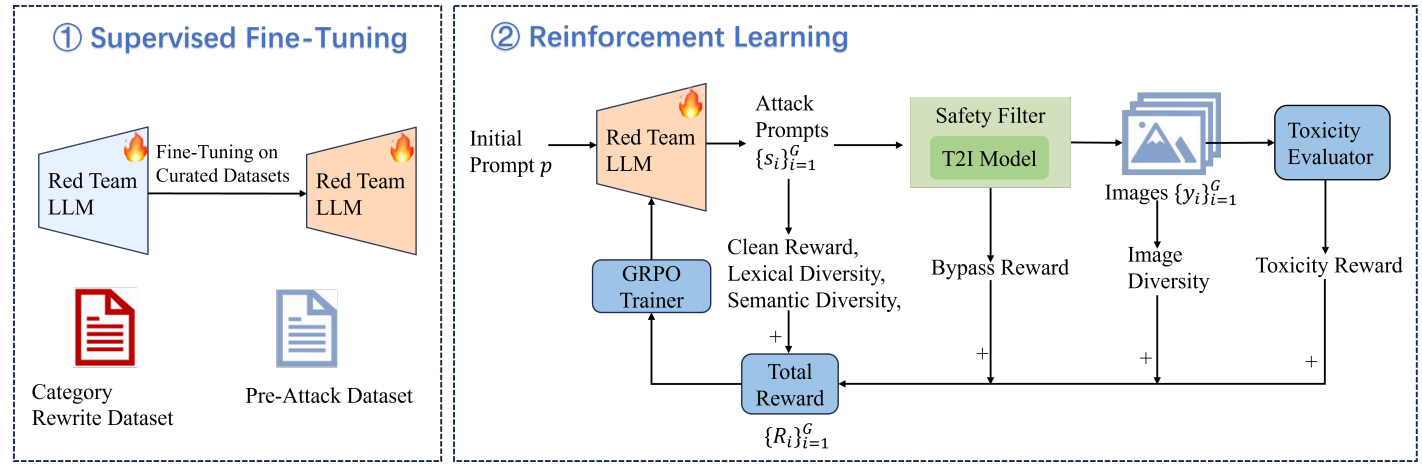
诸如Stable Diffusion之类的文生图(T2I)模型发展迅猛,现已被广泛应用于内容创作领域。然而,这类技术存在被滥用于生成裸体、暴力等违规内容的风险,带来了重大安全隐患。虽然大多数平台部署了内容审核系统,但攻击者仍可能利用底层漏洞进行突破。当前针对T2I模型的红队测试与对抗攻击研究存在关键局限:现有方法难以在提示词隐蔽性与生成图像的高毒性之间取得平衡。部分研究虽成功生成高毒性图像,但使用的对抗性提示词或其生成的图像易被安全过滤器检测拦截;另一些研究专注于提升隐蔽性以绕过安全机制,却难以产出真正有害的内容,忽视了对高危漏洞的发掘。这导致业界仍缺乏评估配备防御机制的T2I模型的安全性的可靠工具。为填补这一空白,我们提出GenBreak框架——通过微调红队大语言模型来系统化探索文生图模型的潜在漏洞。该方法首先在精选数据集上进行监督微调,再通过与代理T2I模型交互进行强化学习,整合多重奖励信号引导LLM生成兼具规避能力与图像毒性的对抗性提示词,同时保持提示词的语义连贯性与多样性。实验表明,这些提示词在黑盒迁移攻击场景下对商用T2I模型表现出高威胁性,有效揭示了实际部署中存在的安全缺陷。
论文作者:王子龙,郑翔,王晓森,王博,马兴军
论文链接:
https://arxiv.org/pdf/2506.10047
8.可信具身智能研究院CVPR 2026:OmniLottie:基于参数化Lottie词元的矢量动画生成
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在矢量动画生成领域取得重要进展,相关成果以“OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens”为题发表于人工智能领域顶级会议CVPR。
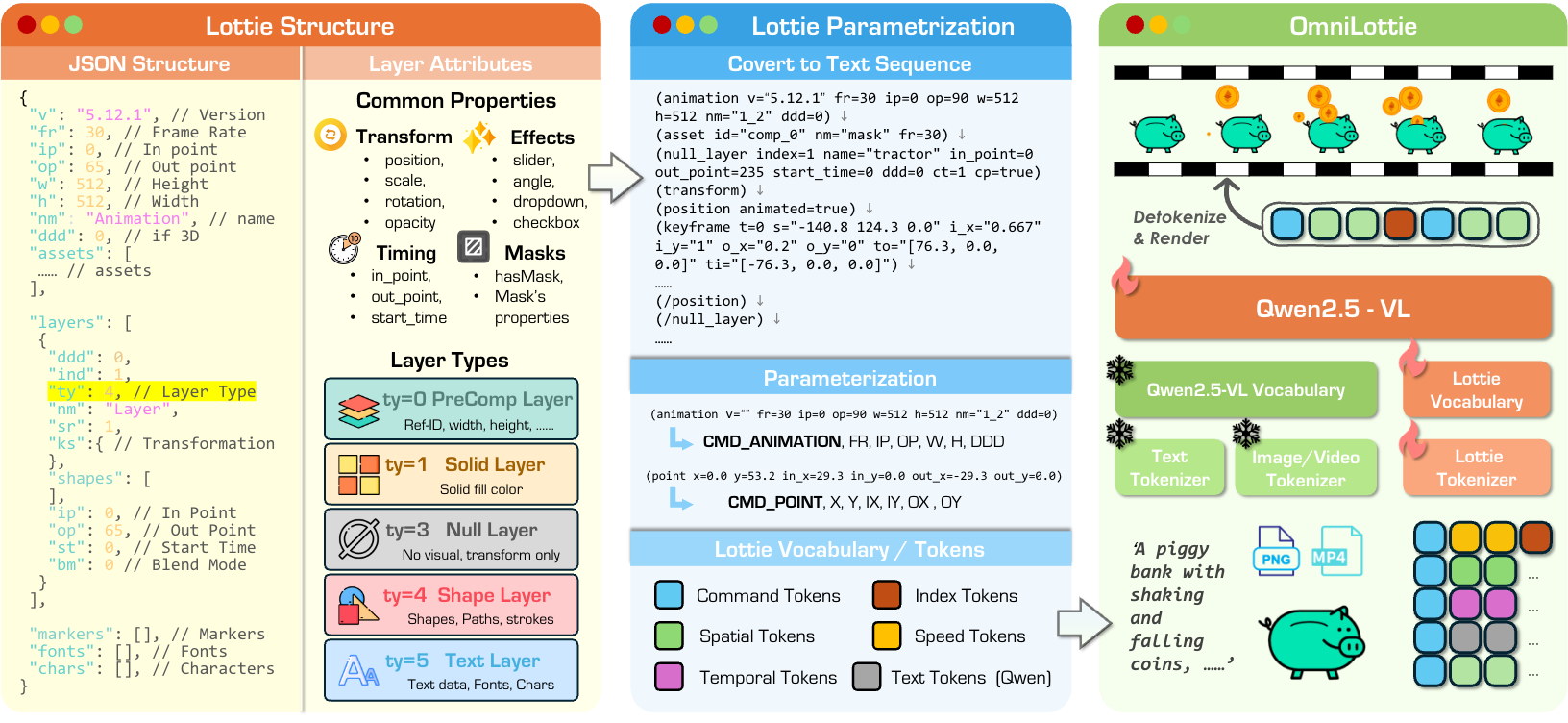
OmniLottie是一个多功能框架,能够根据多模态指令生成高质量的矢量动画。为了灵活控制动画的运动和视觉内容,我们将重点放在了 Lottie,这是一种用于表示形状和动画行为的轻量级 JSON格式。然而,原始的 Lottie JSON文件包含大量固定的结构元数据和格式化标记,这为学习和生成矢量动画带来了巨大的挑战。因此,我们引入了一种精心设计的 Lottie分词器(tokenizer),将 JSON文件转换为结构化的命令与参数序列,用以表示形状、动画函数和控制参数。借助该分词器,我们能够在预训练的视觉-语言模型基础上构建OmniLottie,使其能够遵循多模态交错指令,从而生成高质量的矢量动画。为了进一步推动矢量动画生成领域的研究,我们构建了 MMLottie-2M,这是一个大规模数据集,包含大量专业设计的矢量动画以及相匹配的文本与视觉标注。通过大量实验,我们验证了OmniLottie能够紧密遵循人类的多模态指令,生成生动且语义一致的矢量动画。
论文作者:杨依颖,程巍,陈思锦,付泓豪,曾仙芳,蔡雨君,俞刚,马兴军
论文链接:https://arxiv.org/abs/2603.02138
论文主页:https://openvglab.github.io/OmniLottie/
代码:https://github.com/OpenVGLab/OmniLottie
9.可信具身智能研究院CVPR 2026:基于视频思考:将视频生成作为一种极具潜力的多模态推理范式
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在多模态推理领域取得重要进展,相关成果以“Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm”为题发表于人工智能领域顶级会议CVPR。
“Thinking with Text”和“Thinking with Images”范式已大幅提升了大语言模型(LLMs)和视觉语言模型(VLMs)的推理能力,但它们仍有局限:(1)静态图像无法展现动态过程;(2)文本与视觉模态的割裂阻碍了统一理解与生成。为克服这些局限,我们提出了“Thinking with Video”这一新推理范式,借助Sora-2等视频生成模型,以视频帧为统一媒介进行多模态推理,打破视觉与文本的界限。在我们设计的 VideoThinkBench上,Sora-2展现了卓越的推理能力。在视觉任务上,Sora-2的表现不仅总体上媲美当前SOTA VLMs,更在目测谜题(Eyeballing Puzzles)上比GPT-5高10%;在文本任务上,Sora-2在MATH数据集上的准确率达92%,在MMMU上达到69.2%。我们系统性地分析了这些能力的来源,并发现自一致性(self-consistency)和上下文学习(in-context learning)能够进一步提升视频模型的推理性能。总之,我们的发现证明视频生成模型有统一多模态理解与生成的潜力,而Thinking with Video也有望成为一种统一的多模态推理范式。
论文作者:仝竞奇,牟昱榕,李航成,李明哲,杨永卓,张明,陈麒光,梁天一,胡晓萌,郑逸宁,陈新弛,赵君,黄萱菁,邱锡鹏
论文链接:https://arxiv.org/abs/2511.04570
论文主页:https://thinking-with-video.github.io/
代码仓库:https://github.com/tongjingqi/Thinking-with-Video
测试基准:https://huggingface.co/datasets/OpenMOSS-Team/VideoThinkBench
10.可信具身智能研究院CVPR 2026:FluxMem:面向流式视频理解的自适应分层记忆
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在流式视频理解领域取得重要进展,相关成果以“FluxMem: Adaptive Hierarchical Memory for Streaming Video Understanding”为题发表于人工智能领域顶级会议CVPR。
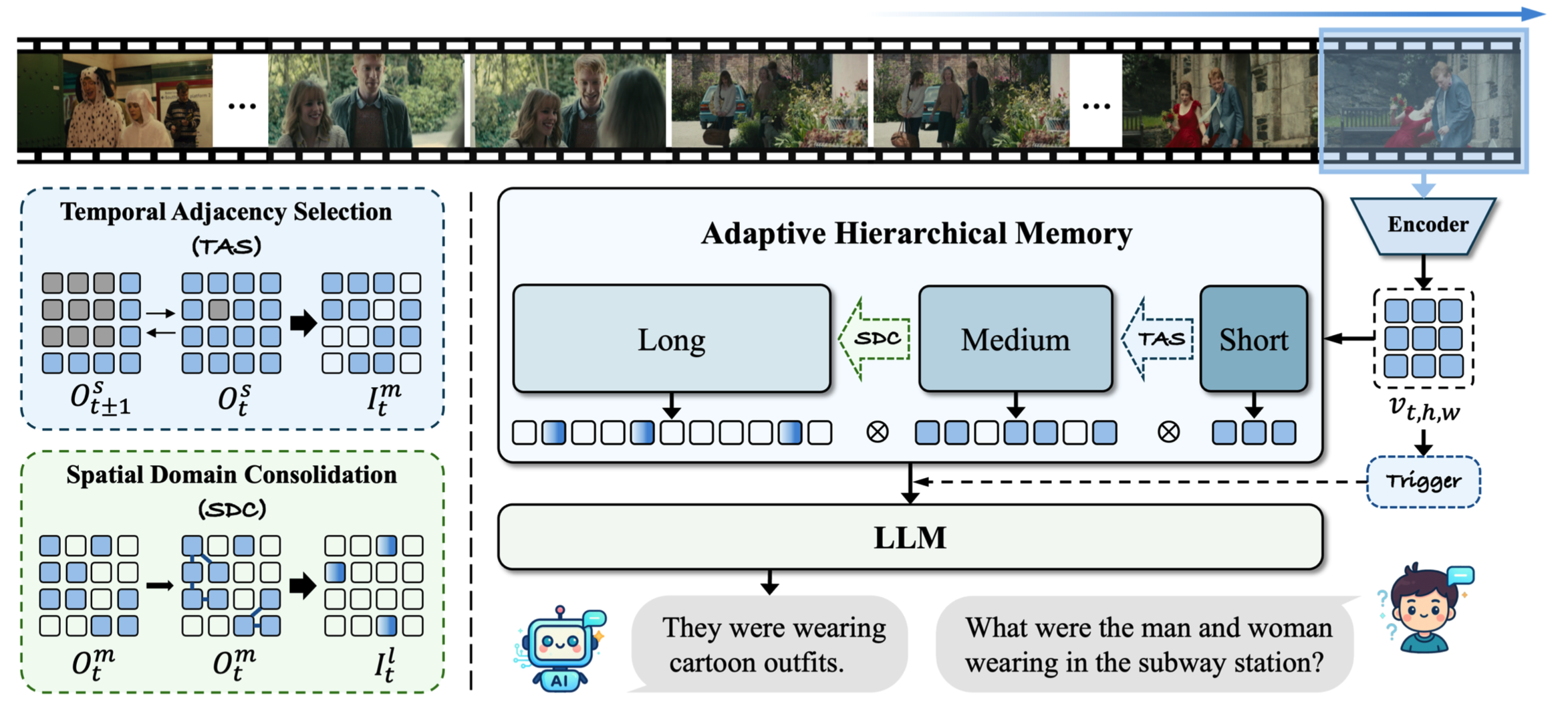
本文提出了FluxMem,一个无需训练的高效流式视频理解框架。FluxMem通过分层的两阶段设计自适应地压缩冗余视觉记忆:(1)时间邻域选择(TAS)模块去除相邻帧之间的冗余视觉词元;(2)空间邻域整合(SDC)模块进一步将每帧内空间上重复的区域合并为紧凑表示。为了有效适应动态场景,我们在TAS和SDC中均引入了自适应词元压缩机制,该机制根据场景的内在统计特性自动确定压缩率,而无需人工调参。大量实验表明, FluxMem在现有在线视频基准测试上取得了新的最优结果,在实时场景中,StreamingBench上达到76.4,OVO-Bench上达到67.2,同时在OVO-Bench上将延迟降低了69.9%,峰值GPU显存减少了34.5%。此外,该方法在离线场景中同样保持了优异性能,在MLVU上取得73.1的成绩,同时减少了65%的视觉词元使用量。
论文作者:谢易蓊,何博,王君可,郑翔宇,叶子逸,吴祖煊
论文链接:https://arxiv.org/abs/2603.02096
论文主页:https://yiwengxie.com/FluxMem/
论文代码:https://github.com/YiwengXie/FluxMem
11.可信具身智能研究院CVPR 2026:HandWorld:以人手为中心的视频动作统一生成
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在视频动作生成领域取得重要进展,相关成果以“HandWorld:Hand-Centric Unified Video Motion Generation”为题发表于人工智能领域顶级会议CVPR。
手物交互是人类与世界互动的基础,理解该场景下手部动作与第一视角视频之间的联系,对于具身智能模型学习人类感知、模拟与规划能力至关重要。然而,由于手部动作与第一视角视频之间存在非线性关系,在二者之间进行联合学习与预测具有较大挑战。在本工作中,我们提出了HandWorld,一个聚焦手物交互场景的统一生成式框架,对第一视角视频与手部动作进行联合建模。HandWorld通过一个双分支条件网络学习跨模态的共享条件表示,该网络融合了视频域与动作域的信息。同时,我们引入基于MANO渲染的手部表示作为中间输入,以进一步增强跨模态的一致性。在共享表示的条件下,模型分别训练两个解耦的扩散Transformer,用于各自模态的预测。灵活的训练策略使模型能够适应多种任务配置,包括可控视频生成与动作预测。我们在大规模第一视角手物体交互数据集上进行了充分的实验,HandWorld在视频合成质量与动作预测精度方面均表现优异,并在多种场景下超越了现有方法。
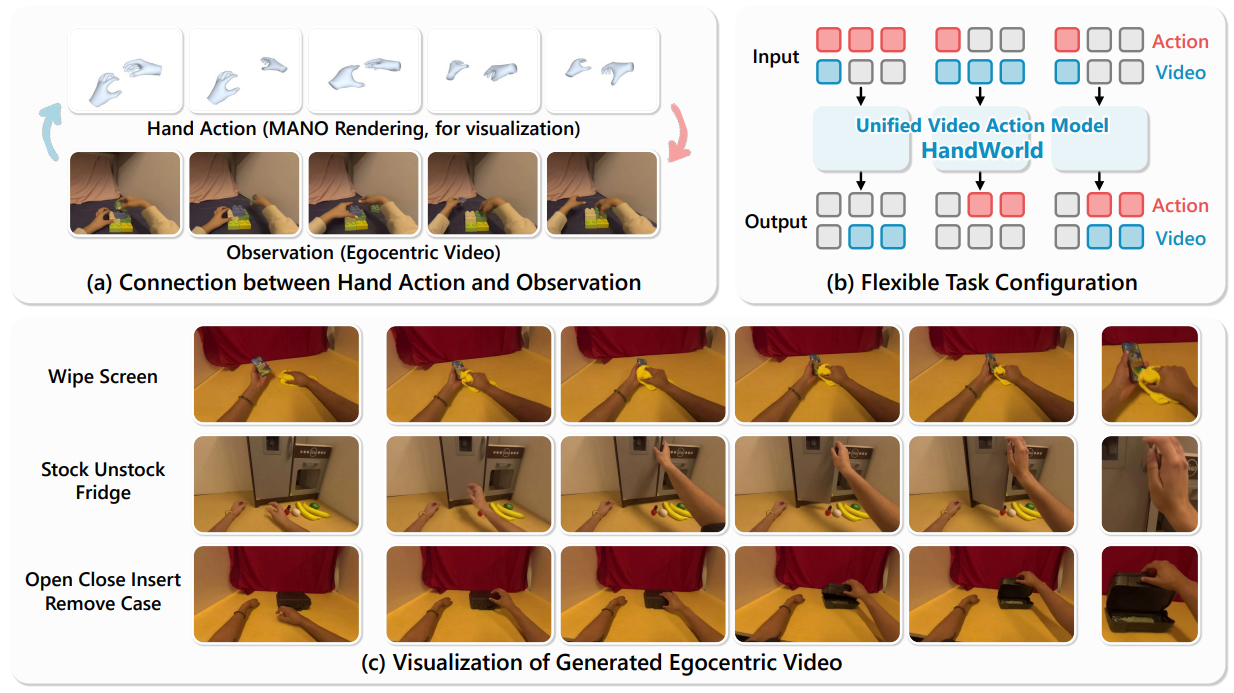
论文作者:孙志豪,杜智颖,杨希桐,吴祖煊
12. 可信具身智能研究院CVPR 2026:融合多样化仿真与自进化模块的场景文本识别数据合成引擎
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在场景文本识别领域取得重要进展,相关成果以“What Is Wrong with Synthetic Data for Scene Text Recognition? A Strong Synthetic Engine with Diverse Simulations and Self-Evolution”为题发表于人工智能领域顶级会议CVPR。
大规模、类别均衡的文字数据是训练高性能场景文本识别模型的关键所在,而直接使用真实场景数据难以满足该要求。合成数据标签精确、成本低廉,是极佳的替代方案。但基于现有合成数据训练的模型性能仍存在明显短板,说明真实数据与合成数据之间存在显著的域差异问题。针对上述问题,我们首先深入分析了现有文字数据合成引擎,指出当前方法在字体多样性、文字语义和布局丰富度上有不足,是造成基于合成数据集训练的识别模型精度大幅落后于基于真实数据训练的模型的关键。基于此,本文在字体、背景和语义丰富度三个维度进行了针对性设计,构建了一套高逼真文字实例渲染合成管线UnionST和相应的大规模合成数据集UnionST-S。我们的合成数据集相较于现有合成数据集,大幅提升了所训练模型的识别精度。本文进一步设计了自进化学习框架,利用合成数据实现真实样本的高效标注。结合自进化学习框架后,模型仅与9%的真实带标注数据混合训练后,即可训练出与当前最强模型相当的识别精度。
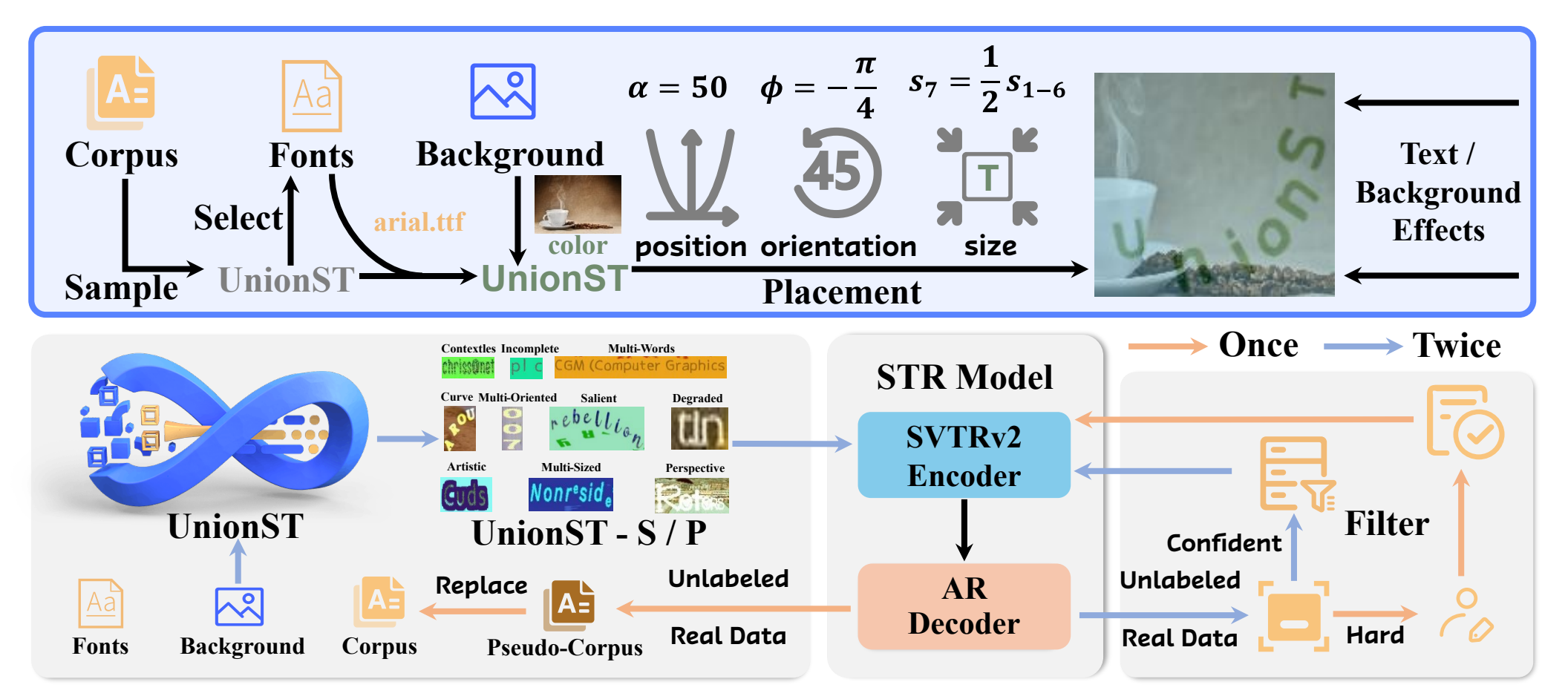
论文作者:叶兴松,杜永坤,张家鑫,李琛,吕静,陈智能
论文链接:https://arxiv.org/abs/2602.06450
代码:https://github.com/YesianRohn/UnionST
13.可信具身智能研究院CVPR 2026:CaTok:基于MeanFlow的因果式图像一维分词器
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在图像分词领域取得重要进展,相关成果以“CaTok: Taming Mean Flows for One-Dimensional Causal Image Tokenization”为题发表于人工智能领域顶级会议CVPR。自回归语言模型以因果式分词为基础,但要将这一范式直接迁移到视觉领域仍然存在挑战。现有的视觉分词器要么将二维图像展平成非因果的一维序列,要么依赖启发式的规则对图像编码的顺序进行约束,而这些顺序往往与“下一词元预测(next-token prediction)”的训练范式不匹配。近期出现的扩散自编码器也未能很好解决上述矛盾:若解码阶段对任意词元等价可见 ,则因果约束随之失效;而采用 nested dropout 方法虽可部分引入因果性,却容易造成训练信号分配不均、学习过程失衡。针对这些问题,我们提出 CaTok,一种结合 MeanFlow 解码器的一维因果图像分词器。CaTok 选择一个区间段而非全部的词元来进行训练,并将选取过程与 MeanFlow 目标函数紧密耦合,从而学习到满足因果约束的视觉一维表征。该表征既支持高效率的一步生成,也能够通过多步采样获得高质量重建;同时,不同词元区间能够自然承载不同层级与类型的视觉语义,实现对多样视觉概念的有效刻画。

论文作者:
陈义桐,吴祖煊,邱锡鹏,姜育刚
论文链接:
https://sharelab-sii.github.io/catok-web/
14.可信具身智能研究院CVPR 2026:FlashMotion:基于轨迹引导的少步可控视频生成
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在视频生成领域取得重要进展,相关成果以“FlashMotion: Few-Step Controllable Video Generation with Trajectory Guidance”为题发表于人工智能领域顶级会议CVPR。
近期,轨迹可控视频生成取得了显著进展。现有方法大多基于adapter架构,以实现沿预定义轨迹的精确运动控制,但均依赖多步去噪过程,带来较高的时间冗余和计算开销。尽管已有视频蒸馏方法能够将多步生成器压缩为少步模型,但直接应用于轨迹可控生成时,会在视频质量和轨迹精度上出现明显下降。为此,我们提出FlashMotion,一种面向少步轨迹可控视频生成的训练框架。首先,在多步生成器上训练轨迹adapter以获得精确控制;随后,将生成器蒸馏为少步模型以加速生成;最后,通过结合扩散与对抗目标的混合策略对adapter进行微调,使其适配少步生成器,从而生成高质量且轨迹准确的视频。此外,我们构建了FlashBench基准,用于评估长序列轨迹可控视频生成,在不同前景目标数量下同时衡量视频质量与轨迹精度。实验结果表明,FlashMotion在视觉质量和轨迹一致性方面均优于现有视频蒸馏方法及多步模型。
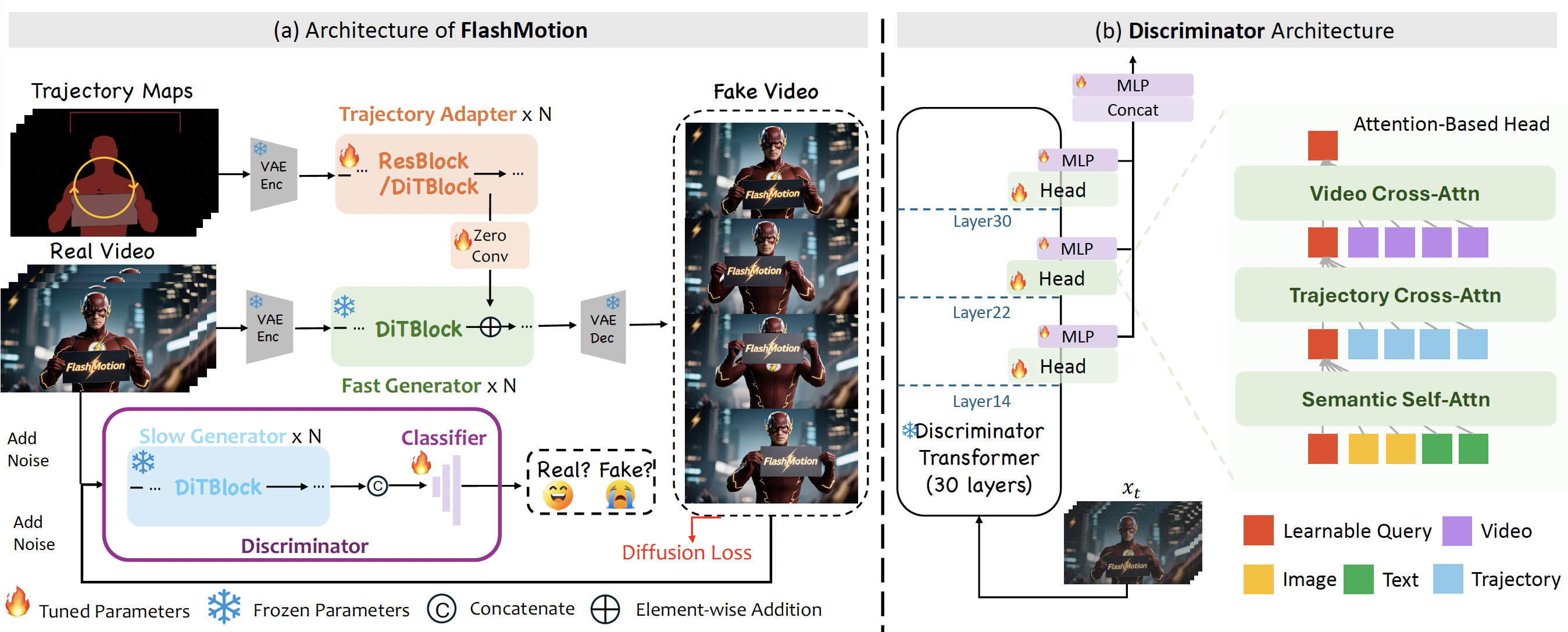
论文作者:李全昊,邢桢,王锐,曹海东,戴琦,董道国,吴祖煊
论文链接:https://arxiv.org/abs/2603.12146
论文主页:https://quanhaol.github.io/flashmotion-site/
代码:https://github.com/quanhaol/FlashMotion
15.通过激活重放提升大规模多模态模型的推理能力
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在多模态模型推理领域取得重要进展,相关成果以“Boosting Reasoning in Large Multimodal Models via Activation Replay”为题发表于人工智能领域顶级会议CVPR。
近年来,基于可验证奖励的强化学习(RLVR)已成为提升多模态大模型推理能力的一种有效方法。然而,这一后训练范式背后的机制仍缺乏深入研究。本文首先从logit lens视角出发,探究对输入激活的影响。我们在多个经过后训练的多模态大模型上进行了系统性研究,结果表明RLVR会相对较多地改变低熵激活,而对高熵激活的影响相对较小。通过可控实验,我们进一步证明这一现象与多模态大模型的推理能力密切相关,表明对低熵激活进行调控可能具有潜在益处。基于上述发现,我们提出了Activation Replay(激活重放),一种新颖、简单且高效的免训练方法,在无需昂贵策略优化的情况下,显著提升后训练大模型的多模态推理能力。该方法在测试阶段对视觉词元进行操作,将基础模型输入上下文中的低熵激活进行重放,用以调控RLVR模型的行为。激活重放在多种场景中均能触发更优的推理表现,包括数学推理、类似o3的视觉智能体任务以及视频推理任务。我们进一步的实验表明,该方法能够提升Pass@K指标,并缓解RLVR在推理覆盖范围上的收窄问题。同时,我们还将该方法与多种替代方案进行对比,例如重放高熵激活而非低熵激活,或直接进行跨模型干预而非操作输入词元,实验结果均验证了我们方法的优越性。
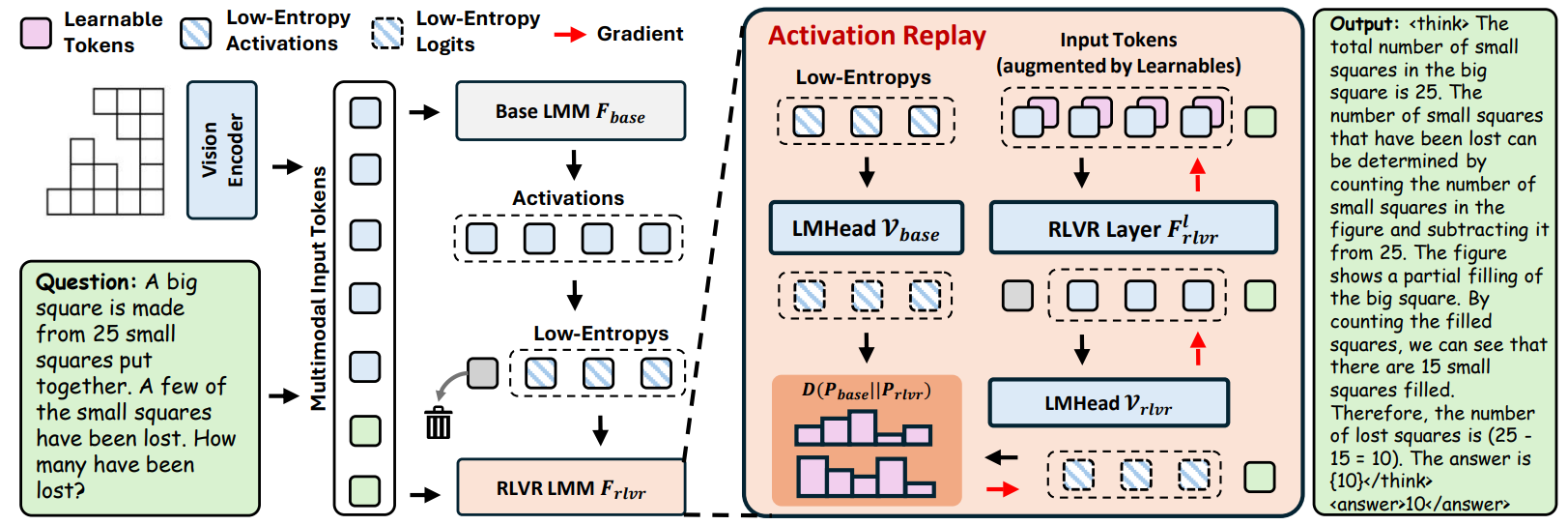
论文作者:邢云,胡晓彬,何庆东,张江宁,颜水成,陆世建,姜育刚
论文链接:https://arxiv.org/pdf/2511.19972
论文主页:https://christian42mmreason.github.io/replay
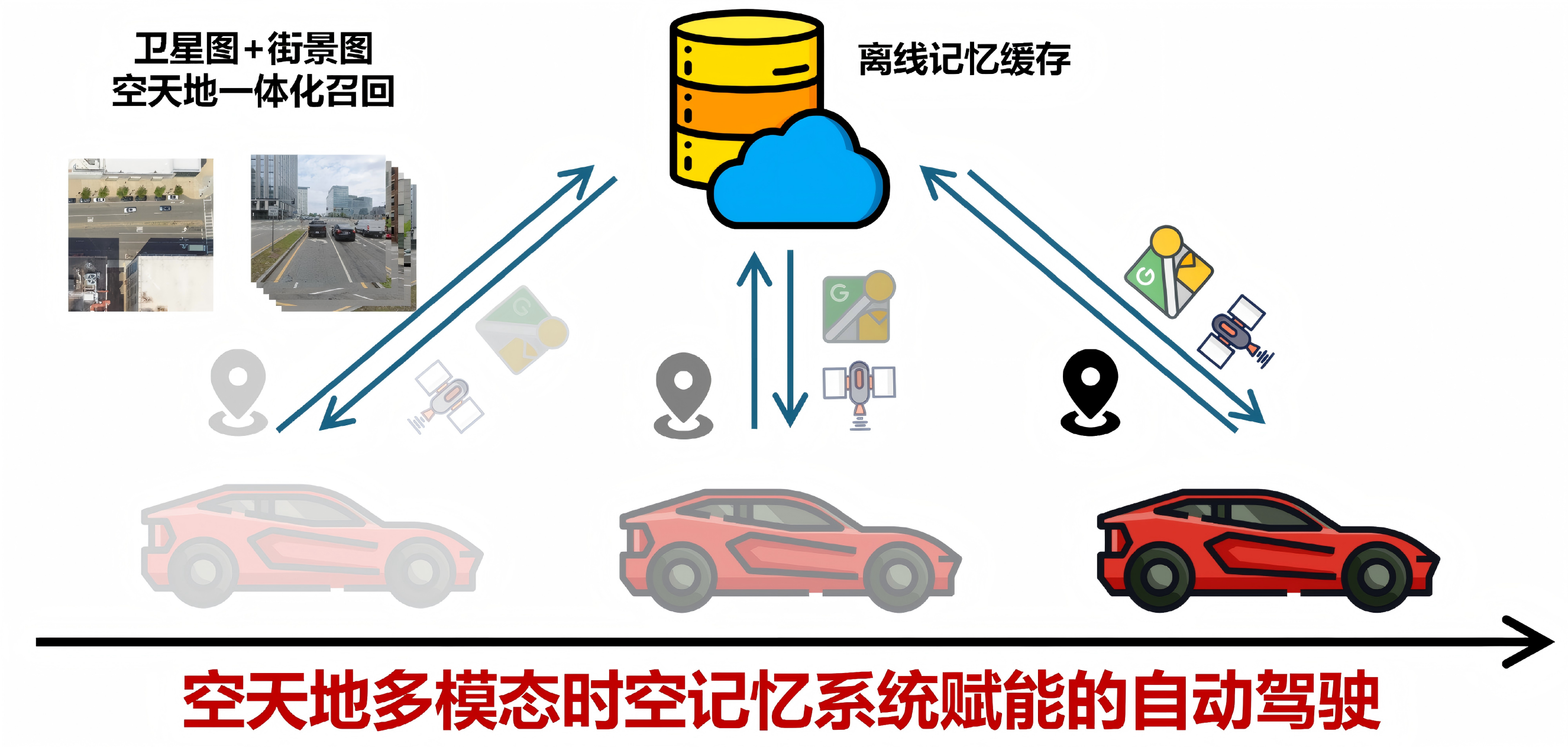
16.空间检索增强的自动驾驶
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在自动驾驶领域取得重要进展,相关成果以“Spatial Retrieval Augmented Autonomous Driving”为题发表于人工智能领域顶级会议CVPR。
现有自动驾驶系统主要依赖车载传感器(如摄像头、激光雷达、IMU等)进行环境感知。然而,这一范式受限于行驶时的感知范围,在视野受限、遮挡严重或极端条件(如黑暗、雨天)下往往表现不佳。相比之下,人类驾驶员即使在能见度较低的情况下,仍能够回忆道路结构信息。为赋予模型类似的“回忆”能力,本文提出空间检索范式,通过引入离线检索的地理图像作为额外输入。这些图像可从离线缓存中便捷获取(例如街景地图或已有自动驾驶数据集),无需额外传感器,从而可作为现有自动驾驶任务的一种即插即用扩展。在实验方面,首先基于Google Maps API检索地理图像,对nuScenes数据集进行扩展,并将新增数据与自车轨迹进行对齐。在此基础上,围绕五个核心自动驾驶任务构建基线,包括目标检测、在线建图、占用预测、端到端规划以及生成式世界建模。大量实验结果表明,引入该空间检索模态能够在部分任务上带来性能提升。数据集构建代码、数据及评测基准已经开源。
论文作者:贾萧松,张宸赫,江雨乐,嵩布尔,张致远,陈晨,张少锋,周煊赫,杨学,严骏驰,姜育刚
论文链接:https://arxiv.org/abs/2512.06865
论文主页:https://spatialretrievalad.github.io/
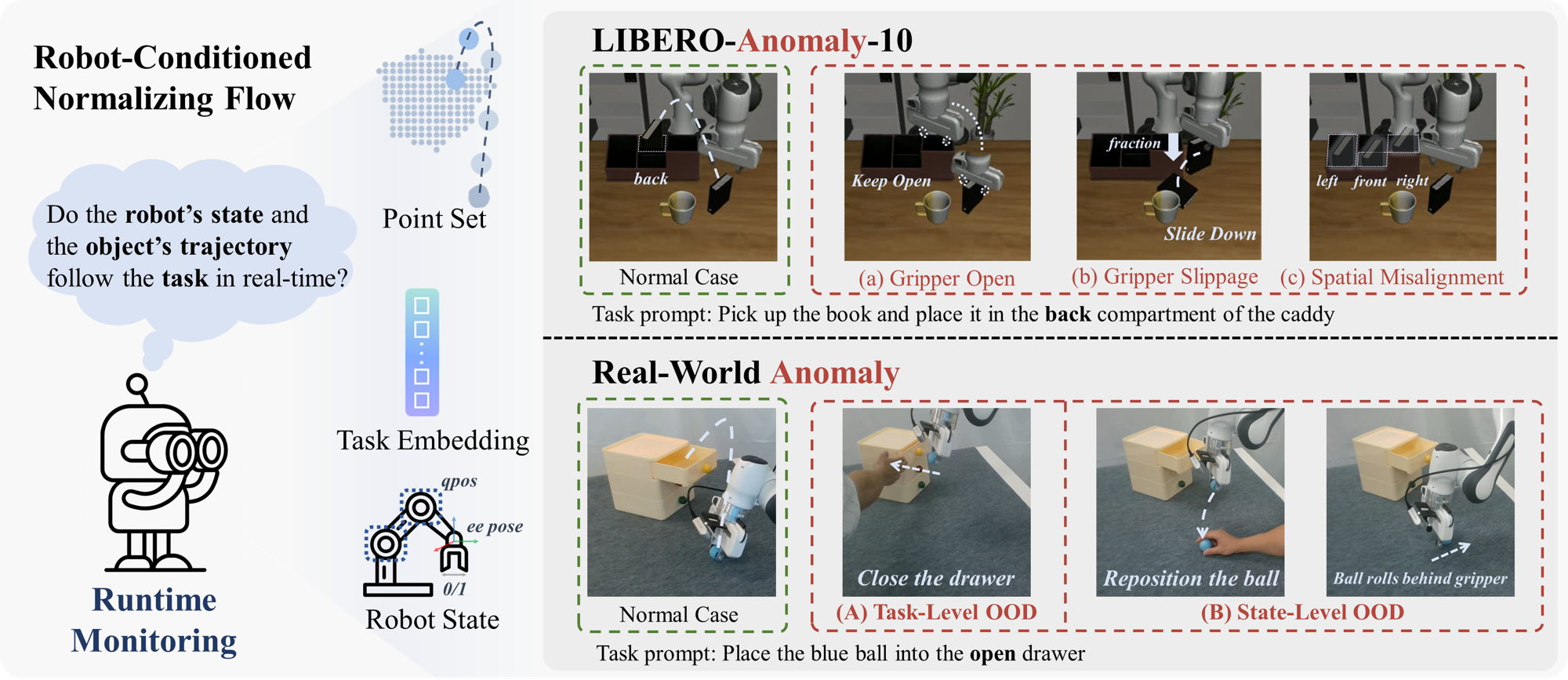
17.RC-NF:一种面向机器人操作实时异常检测的条件化归一化流方法
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在机器人操作异常检测领域取得重要进展,相关成果以“RC-NF: Robot-Conditioned Normalizing Flow for Real-Time Anomaly Detection in Robotic Manipulation”为题发表于人工智能领域顶级会议CVPR。
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)的发展使机器人能够执行日益复杂的任务。然而,通过模仿学习训练的VLA模型在动态环境中的可靠性仍然不足,并且在分布外(Out-of-Distribution, OOD)情形下往往容易失败。为解决这一问题,本文提出了一种机器人条件归一化流模型(Robot-Conditioned Normalizing Flow, RC-NF),用于机器人异常的实时检测与干预。该方法能够确保机器人自身状态与目标物体的运动轨迹与任务要求保持一致。具体而言,RC-NF在归一化流框架中对任务相关的机器人状态与物体状态进行解耦建模,仅依赖正样本即可实现无监督训练,并在推理阶段通过概率密度函数计算精确的机器人异常评分。此外,本文提出了一个用于仿真评估的基准数据集LIBERO-Anomaly-10,涵盖三类典型的机器人异常情况。实验结果表明,与现有方法相比,RC-NF在各类异常检测任务中均达到了当前最优性能。真实世界实验进一步验证了RC-NF可作为VLA模型(例如 pi0)的即插即用模块,在100毫秒以内提供实时的OOD信号,从而支持在必要时进行状态级回滚或任务级重规划。综上所述,RC-NF显著提升了基于VLA的机器人系统在动态环境中的鲁棒性与适应能力。
论文作者:周士杰,朱斌,杨嘉瑞,赵祥宇,陈静静,姜育刚
论文链接:https://arxiv.org/pdf/2603.11106
论文主页:https://heikaishuizz.github.io/RC-NF/
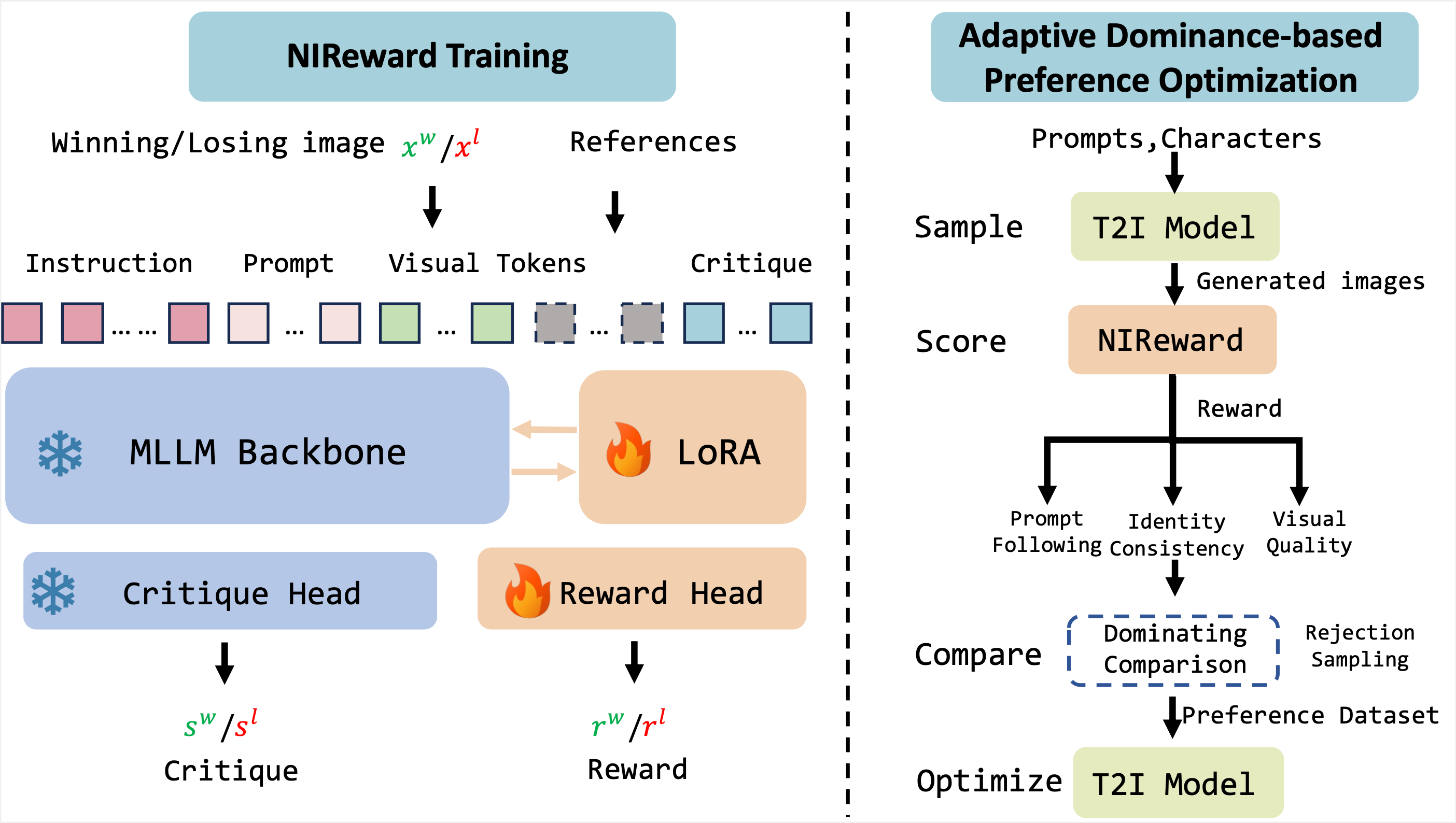
18.面向多维度人类偏好对齐的多角色叙事图像生成
近日,复旦大学智能机器人与先进制造创新学院/可信具身智能研究院在图像生成领域取得重要进展,相关成果以“Aligning Multi-Character Narrative Image Generation with Multi-AspectHuman Preferences”为题发表于人工智能领域顶级会议CVPR。
叙事图像生成旨在创建包含多个不同角色并捕捉其相互关系的图像,这对当前的文本到图像扩散模型提出了重大挑战。通用的个性化方法往往面临语义对齐不佳、身份混淆以及美学失真等问题。现有的评估指标(如CLIP、ArcFace及传统奖励模型)难以充分捕捉上述问题,无法与人类感知偏好保持一致。为了对齐人类偏好,我们首先构建了一个细粒度的人类偏好数据集NI-RLHF,通过收集详细的人工评价与偏好判断,覆盖三个核心维度:提示词遵循度、身份一致性和视觉质量。基于这一数据集,我们训练了一个基于评价反馈的奖励模型NIReward,使其能够生成可解释的图像评估结果。基于NIReward提供的可解释奖励信号,我们进一步提出了自适应优势驱动的偏好优化方法(Adaptive Dominance-based Preference Optimization,ADPO),在多个偏好维度之间实现均衡学习的同时,动态适应奖励差异。实验结果表明,NIReward显著优于现有的评估模型和奖励模型,ADPO在三个关键偏好维度上均实现了显著提升。通过引入NIReward和ADPO,我们的工作为生成真正符合人类偏好的叙事图像开辟了新的道路。
论文作者:高子怡,魏志鹏,陈静静,谭志羽,李昊,Yi-Ping Phoebe Chen
19.张立华团队CVPR 2026:融合主动感知与聚焦推理,构建免训练视觉语言导航新框架
近日,我院张立华教授团队在具身智能与视觉语言导航(VLN)领域取得突破性进展,研究论文《ProFocus: Proactive Perception and Focused Reasoning in Vision-and-Language Navigation》已被CVPR 2026 接受发表。该研究针对现有导航方法被动处理冗余视觉输入且无差别对待历史上下文、导致感知低效与推理失焦的瓶颈 ,提出了 ProFocus 框架。ProFocus 创新性地提出了一种免训练的渐进式架构,通过大语言模型与视觉语言模型的深度协同,实现了“主动感知”与“聚焦推理”的统一。这一框架为提升基础模型在未知复杂物理环境中的导航决策能力提供了全新的技术支撑。
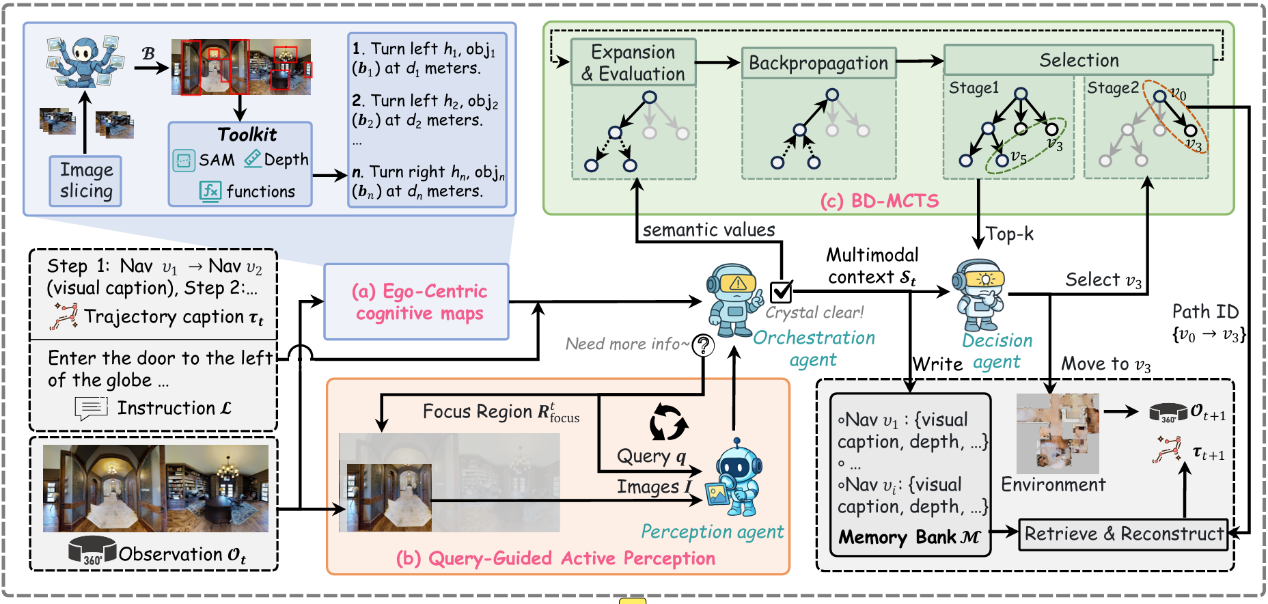
该研究提出了一种免训练的渐进式具身导航框架,有效解决了大模型在复杂物理环境中感知冗余与推理失焦的问题。在主动感知阶段,模型通过将全景视野转化为以自我为中心的语义地图,并构建“感知-推理”闭环,动态且精准地获取决策所需的关键细粒度视觉线索。在聚焦推理阶段,ProFocus引入了分支多样化的蒙特卡洛树搜索(BD-MCTS)机制,模拟人类在寻路时的记忆修剪与优先级回溯行为,增强了决策代理在海量历史上下文中检索与推理高价值路径的能力。ProFocus在 R2R 和 REVERIE 两大权威基准测试的零样本导航任务中均取得SOTA 性能。这一成果不仅突破了视觉语言导航中被动接受全景视觉输入与无差别对待历史记忆的技术瓶颈,也为长视野复杂环境探索及残障辅助机器人等具身智能应用提供了全新的技术范式。
论文第一作者为2024级工程博士薛伟,我院张立华教授与杨鼎康博士为论文的通讯作者
原文链接: https://openreview.net/forum?id=fuyZoUdwwb
20.张立华团队 CVPR 2026:长文档“证据稀疏”怎么解?提出多智能体上下文工程构建证据密集输入的长文档理解新框架SLEUTH
近日,复旦大学张立华教授团队在多模态长文档理解领域取得重要进展,研究论文《Resolving Evidence Sparsity: Agentic Context Engineering for Long-Document Understanding》被CVPR 2026接收发表。论文提出了一种全新的多智能体上下文工程框架—— SLEUTH,系统性解决长文档理解中“证据稀疏、上下文冗余、推理失焦”等关键瓶颈问题。
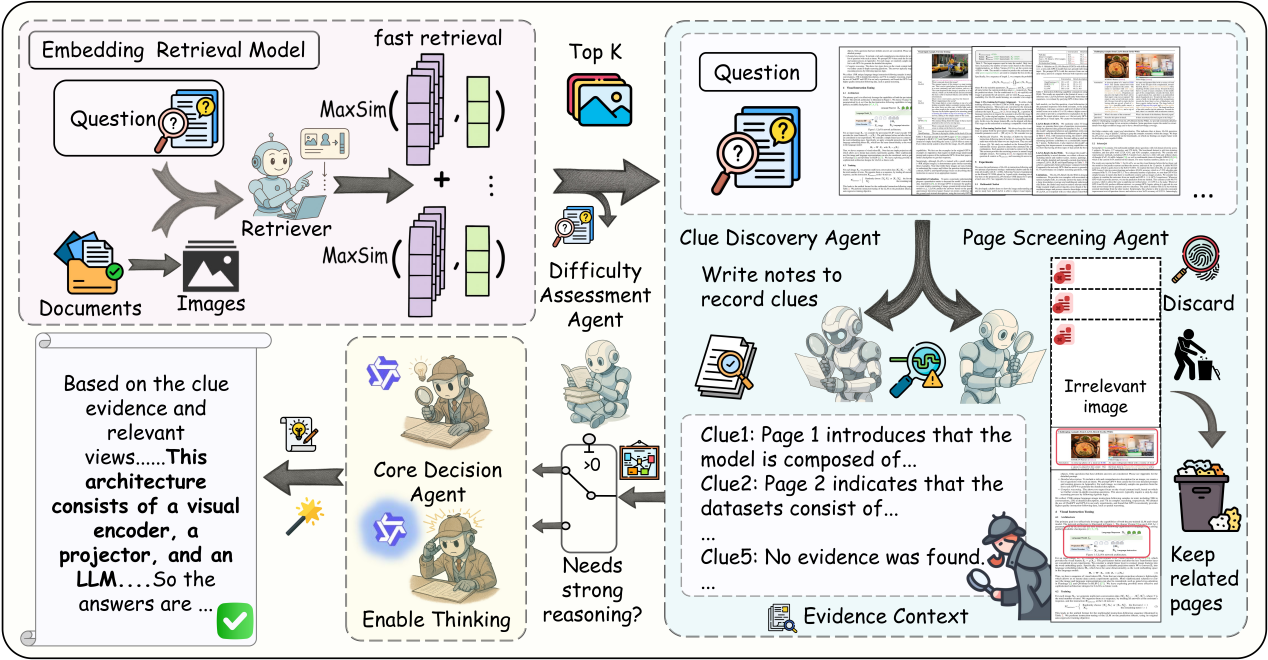
真实长文档场景中,关键信息往往分散在多页、多模态内容中,而大模型在面对长上下文时容易受到冗余干扰甚至产生幻觉。针对这一挑战,SLEUTH 从“上下文构建”的角度出发,提出构建“高密度证据上下文”的新范式,而非单纯依赖更长输入或更大模型规模,为长文档多模态理解提供了全新的技术路径。提出多智能体上下文工程框架SLEUTH 构建了一个“检索收缩 → 线索挖掘 → 视觉筛选 → 难度自适应推理”的层级化流程,通过四个协同智能体对长文档进行逐页精炼处理,在固定上下文长度下最大化证据密度,有效缓解长上下文带来的推理干扰问题。设计双层证据构建机制,实现细粒度线索与全局视觉结构互补,两个智能体分别以页为单位提取结构化证据(文本、表格、图表区域级线索),并保留来源与推理依据;从整体视觉结构层面对页面进行相关性判断,筛除无关图像页面。二者并行协作,在压缩输入规模的同时保留关键视觉与语义信息,实现“少而精”的高质量证据上下文构建。在MMLongBench、LongDocURL、PaperTab、FetaTab四个长文档基准上,SLEUTH在多个主流视觉语言模型骨干下均取得显著提升,取得SOTA性能。相较强 RAG 和多智能体基线方法实现稳定增益,验证了“上下文质量优先于上下文长度”的核心思想。
本研究系统性提出“证据密集型上下文构建”在长文档理解中的核心作用,证明通过结构化证据提炼与视觉语义协同筛选,可以在不改变模型架构、不进行额外训练的情况下显著提升多模态长上下文推理能力。
2025级直博生刘科良为本论文的第一作者。我院张立华教授与杨鼎康博士为本论文通讯作者。
原文链接:https://arxiv.org/abs/2511.22850
21.张立华团队CVPR 2026:融合诊断语义与原型控制,构建超越像素模拟的病理图像生成新框架
近日,复旦大学张立华教授团队在计算病理学与生成式人工智能领域取得突破性进展。针对现有病理学图像生成模型过度依赖像素级模拟、缺乏精确细粒度语义控制以及面临医学术语异质性等瓶颈问题,该团队提出了名为 UniPath的全新语义驱动病理图像生成理解统一框架。UniPath创新性地利用成熟的诊断理解模型(病理学 MLLM)来引导可控生成,实现了理解与生成的统一。这一框架不仅极大地缓解了高质量图文数据稀缺的难题,更为提升大模型在复杂病理环境中的形态学控制力提供了全新的技术支撑。
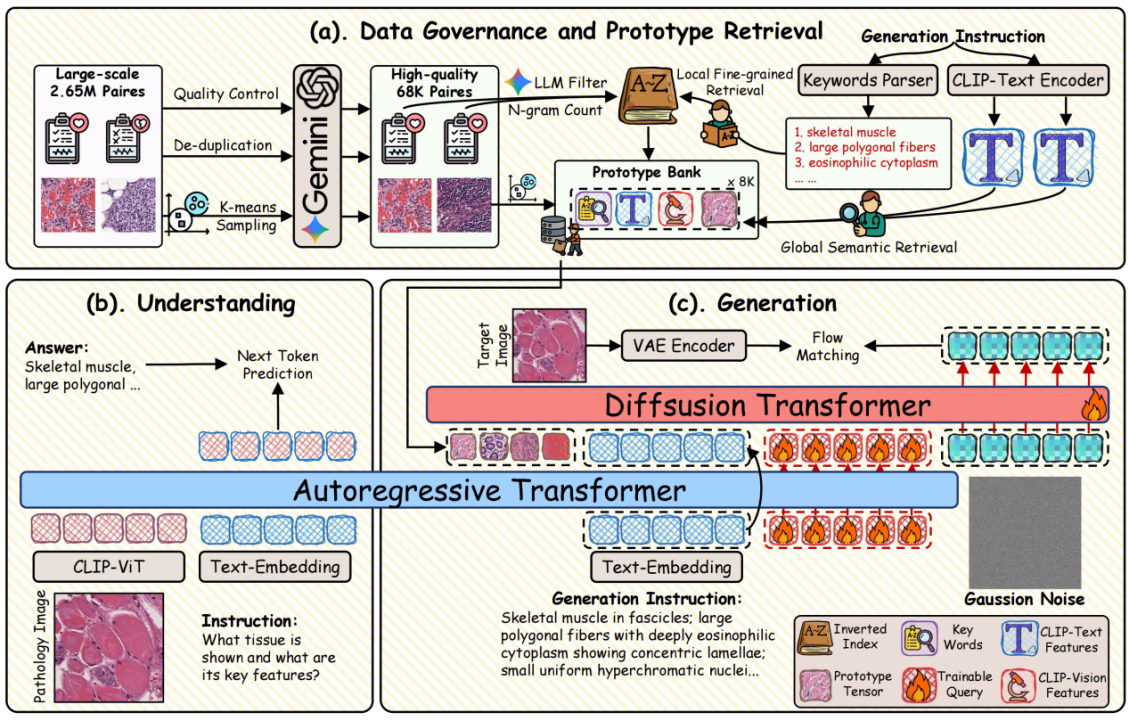
该研究提出了一种免于传统非语义条件限制的生成框架,有效解决了大模型在病理图像生成中缺乏诊断感知与形态控制失焦的问题。在架构设计上,UniPath引入了独创的多流控制机制。该机制通过“原始文本流”保留多样化输入指令;通过“高级语义流”从冻结的病理大语言模型中提取抗改写的诊断语义 Token;并通过“原型流”引入非参数化的原型库,实现了对腺体结构、核异型性等关键特征的组件级形态控制。在数据与评估层面,团队不仅构建了包含 265 万图文对的大规模预训练语料库及 6.8 万的高质量精标注子集,还建立了一套为病理学量身定制的四层评估体系。实验结果表明,UniPath取得了 SOTA的生成保真度表现,其 Patho-FID 指标达到 80.9,比第二名大幅提升了 51%,并在细粒度语义控制上达到了真实图像 98.7% 的性能。这一成果不仅突破了现有模型仅注重视觉真实感的局限,也为计算病理学的数据增强、医学教育及病理特征探索提供了全新的技术范式。
2022级博士生韩铭浩与2026硕士生刘奕辰为本论文的第一作者,我院张立华教授与杨鼎康博士为本文的通讯作者。
原文链接:https://arxiv.org/abs/2512.21058
22.张立华团队CVPR 2026:锻造多模态大模型动态记忆,构建面向通用医学视觉大模型的检索引导持续学习框架
近日,复旦大学张立华教授团队在医学VLM领域取得重要进展。针对医学基础模型在持续学习过程中面临的微细领域内特征遗忘以及显著跨领域分布差异这两大核心挑战,该团队提出了名为 PRIMED的全新框架。该研究将检索增强生成(RAG)技术引入医学持续学习,通过构建包含千万级医学图文对检索库及 3000 条精细化医学问题,为模型的增量训练提供实时、动态的知识导航。实验结果表明,PRIMED 在医学通用任务增量学习基准测试中全面超越了现有方法,显著提升了模型在临床多场景切换中的适应能力与知识保留。
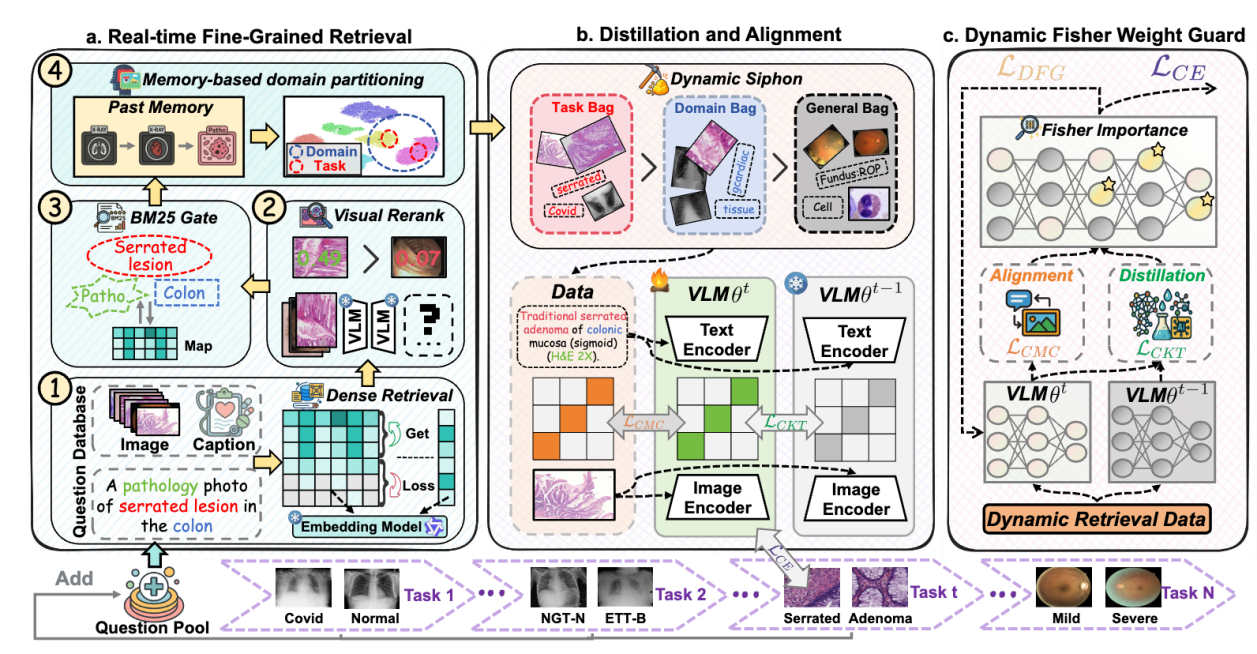
该研究提出首个医疗视觉语言大模型持续学习框架,通过构建1800万规模的医学检索库并首创性地将动态多级RAG系统引入持续学习,利用其特有的Dynamic Siphon机制精准调取任务、领域及通用三类知识流,实现了对集群化医学知识的解耦与针对性强化 ;同时,框架结合了对比知识迁移(CKT)与跨模态一致性(CMC)损失策略,并引入动态Fisher权重保护(DFG)算法来实时评估并约束关键参数,在确保模型高效获取新知识的同时,有效缓解了灾难性遗忘并保留了基础模型的零样本能力 ;此外,团队还针对性地构建了包含HieraMedTransfer与MedXtreme两个维度的MGTIL基准,填补了医学通用领域跨任务与跨领域持续学习评测体系的空白 。
2024级硕士生陈滋知为本论文的第一作者,我院张立华教授与杨鼎康博士为本论文的通讯作者。
原文链接: https://arxiv.org/abs/2512.13072
23.范佳媛科研团队IEEE TGRS,AdaMixCon: 面向小样本高光谱图像分类的难度感知特征增强

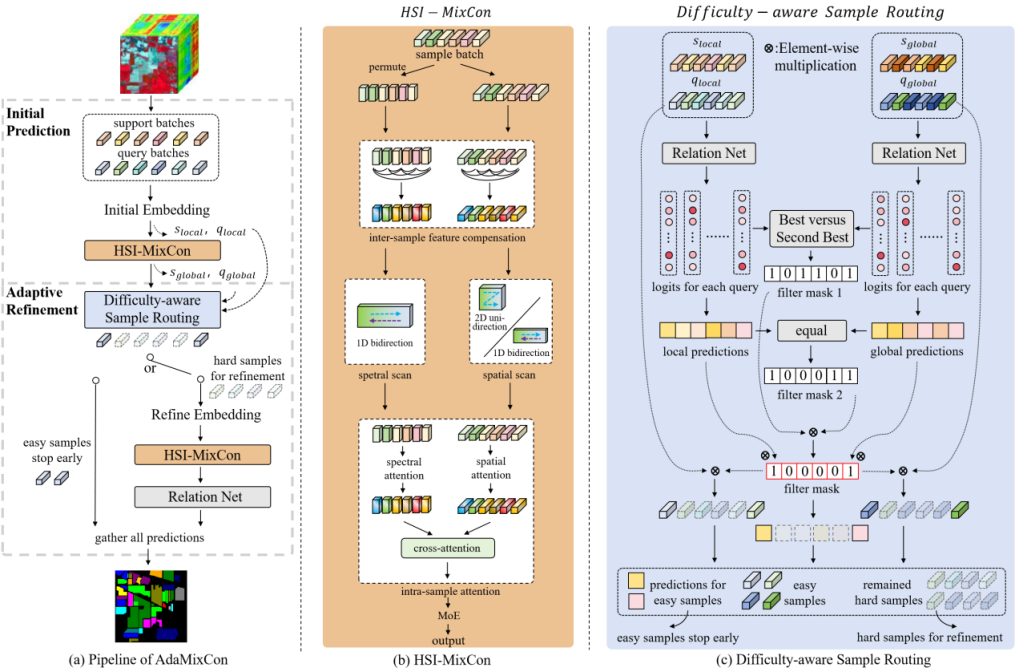
近日,我院范佳媛老师科研团队在小样本高光谱图像分类领域取得重要研究进展。相关研究成果以“AdaMixCon: Difficulty-Aware Feature Enhancement for Few-Shot Hyperspectral Image Classification”为题,发表在国际地球科学与遥感领域权威期刊IEEE Transactions on Geoscience and Remote Sensing。围绕小样本高光谱图像分类中样本依赖关系利用不足与样本难度感知缺失两大关键问题,提出一种自适应难度感知的双阶段框架AdaMixCon,为稀缺标注场景下的地物识别提供高效实用的新方案。对现有方法在处理高光谱图像数据时样本依赖关系利用不足问题,提出光谱-空间特征增强模块,引入样本间注意力与样本内注意力机制,在小样本条件下实现对样本光谱-空间特征的协同建模,有效提升特征的判别性;针对样本难度感知缺失问题,提出难度感知样本路由模块,引入样本路由机制,根据样本难度进行自适应地分类,在对困难样本实现有效分类的同时缓解简单样本的过拟合风险。
原文链接:https://ieeexplore.ieee.org/abstract/document/1137309
24. 超越照明所Microsystems & Nanoengineering: 融合纳米压痕测试与混合 Potts-相场模拟的铜金属化玻璃通孔(TGV-Cu)长期高温老化机制研究
近期,我院超越照明所、上海市碳化硅功率器件工程技术研究中心樊嘉杰青年研究员团队在先进封装可靠性研究领域取得重要进展,相关成果以“Long-term high-temperature aging mechanism of copper-metallized through-glass vias: a combined nanoindentation test and hybrid Potts-phase field simulation study”为题发表于领域高水平期刊《Microsystems & Nanoengineering》。

玻璃基板作为 2.5D/3D 先进封装的重要载体,铜金属化玻璃通孔技术TGV-Cu是下一代高性能、高可靠算力芯片封装的核心技术之一。本文针对TGV-Cu在长期高温老化过程中的性能演化难题,构建了一套实验标定与多尺度模拟相结合的系统性研究框架,通过多维度测试与仿真手段,系统揭示了其在长期高温老化环境下的软化规律与应力演化内在机制。研究中,团队采用空间分辨纳米压痕技术与电子背散射衍射(EBSD)表征方法,精准捕捉并详细描述了TGV-Cu结构孔口区域与中部区域力学性能的显著衰减差异;同时,结合分子动力学(MD)模拟技术深入探究性能衰减的本质,明确验证了晶粒粗化现象是导致TGV-Cu本征强度下降的核心因素。为进一步厘清晶粒演化的动态过程与调控机制,研究团队进一步引入混合Potts–相场模型,创新性地在热-力-塑性耦合条件下,对TGV-Cu的晶粒演化过程进行了精准模拟,阐明由力学各向异性引发的低模量晶粒择优生长机制。研究同时验证了TGV-Cu结构在长期高温老化条件下的电学稳定性。相关结果可为高可靠玻璃中介层封装结构的设计、优化与寿命评估提供重要实验手段参考和模拟仿真支撑。
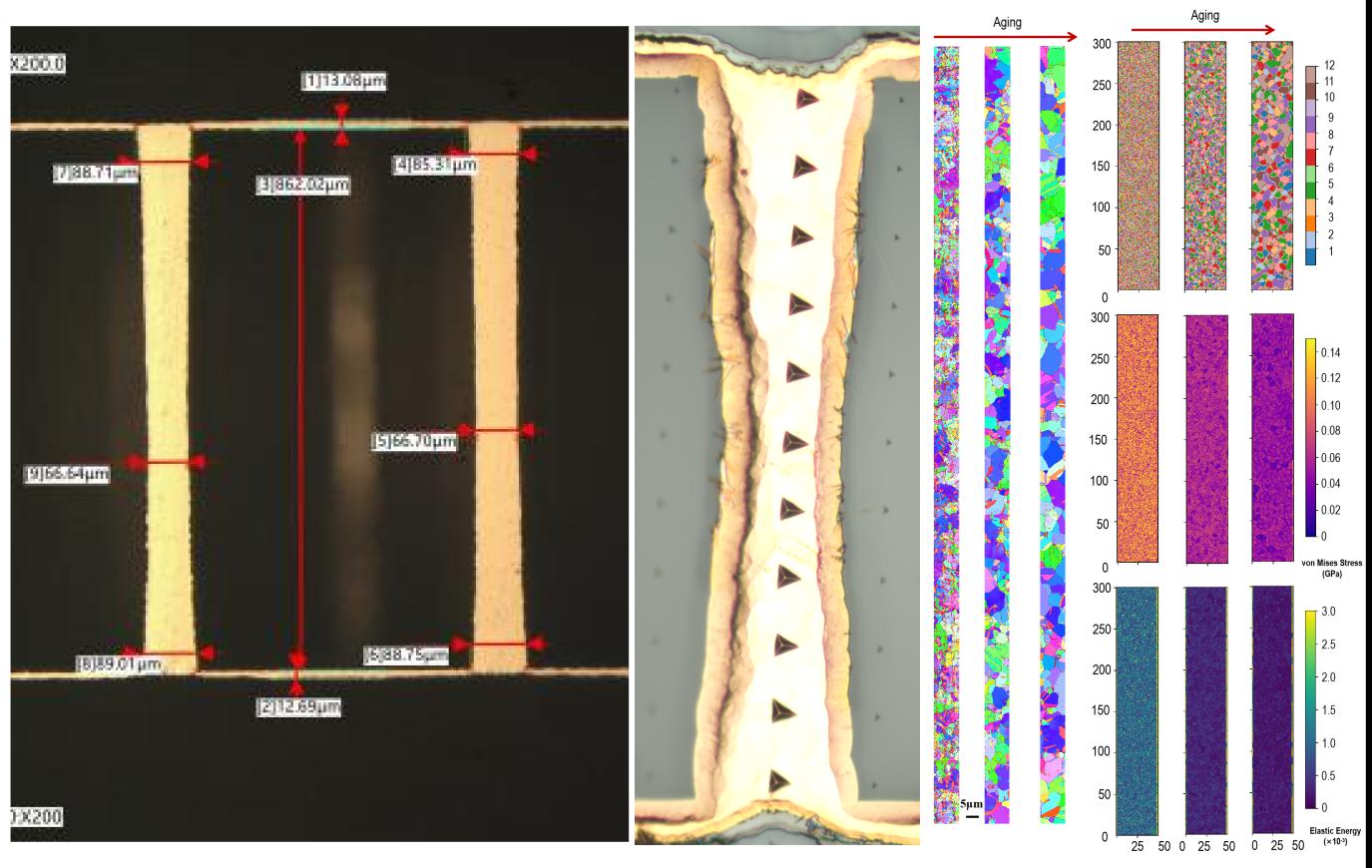
论文第一作者为24级博士生陈俊伟,通讯作者之一为我院樊嘉杰青年研究员。研究得到国家自然科学基金、国家留学基金委等项目资助。
文章链接:https://doi.org/10.1038/s41378-026-01160-0






