
 搜索
搜索


国际计算机视觉大会(International Conference on Computer Vision,ICCV)是计算机视觉领域的顶级会议,与CVPR、ECCV 并称为 “计算机视觉领域的三大顶会”。该会议每两年举办一次,其论文集在谷歌学术全球出版物影响力榜单中位列第十三。ICCV 2025将于10月19日至23日在美国夏威夷檀香山会议中心召开。本次会议收到11239篇有效投稿,经专家严格评审,共录用2698篇论文,录用率为24.0%。复旦大学视觉与学习实验室共有15篇论文入选,成果覆盖具身智能、多模态大模型、图像视频生成、多模态对抗攻防等多个重要研究方向。
01
指令驱动的视频预测
AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
文本引导的视频预测(TVP)旨在根据输入指令和初始帧,对未来帧进行高效且准确的预测,在具身智能数据生成和视频内容创作等领域具有广阔的应用前景。然而,现有方法普遍存在时空一致性不足以及细粒度控制能力较弱等问题。为此,本文充分挖掘了多模态大模型在时空预测方面的潜力,提出了一种能够实现高精度视频状态预测的新方法。具体而言,本文设计了一种基于双查询机制的Transformer结构,实现了指令信息与图像信息的高效融合,从而为未来帧预测提供了高质量的多模态控制条件。此外,本文还提出了时间适配器和空间适配器,能够以极低的训练成本将通用视频扩散模型快速适配到特定应用场景。大量实验结果表明,本文方法在四个公开数据集上均显著优于当前最先进的对比方法。
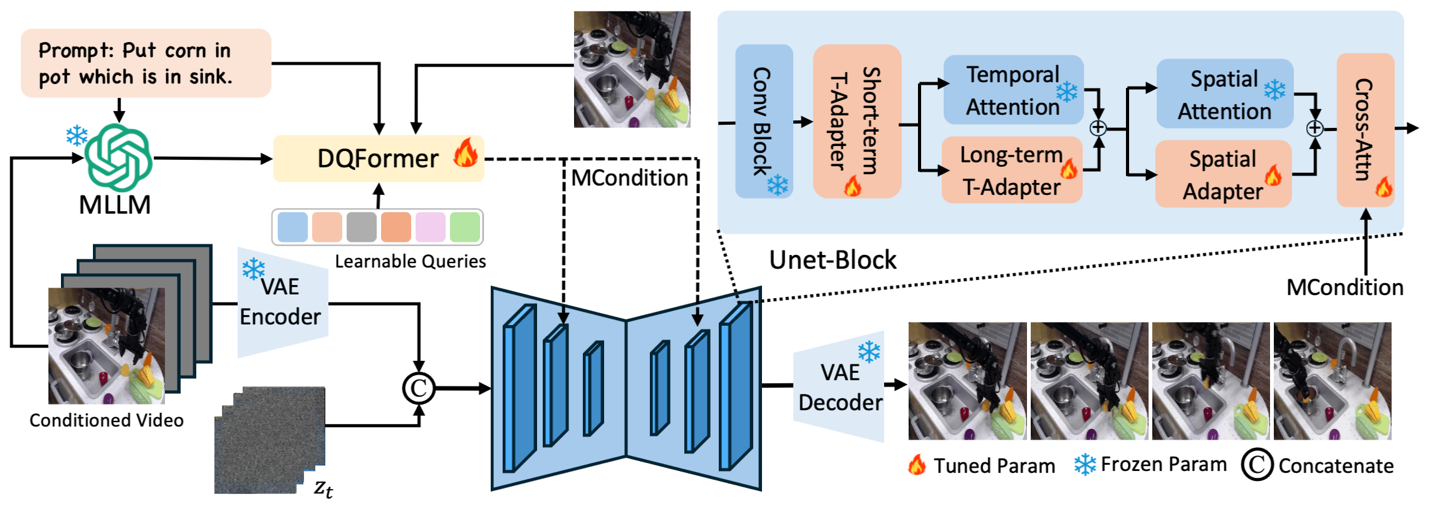
方法框架图
论文作者:
Zhen Xing, Qi Dai, Zejia Weng, Zuxuan Wu, Yu-Gang Jiang
论文链接:
https://arxiv.org/abs/2406.06465
论文源码:
https://chenhsing.github.io/AID
02
Hydra-NeXt:基于开环训练的闭环轨迹预测
Hydra-NeXt: Robust Closed-Loop Driving with Open-Loop Training
端到端轨迹预测在具身智能、自动驾驶等领域具有重要的作用,但如何有效降低开环训练与闭环部署之间的差距是亟待解决的难题。现有方法通常在开环环境中训练轨迹预测模型,但其在闭环环境中难以及时响应其他交通参与者的行为变化。此外,由于开环与闭环环境的差异,这些模型可能生成不符合车辆运动学约束的轨迹。为了解决这一问题,本文提出Hydra-NeXt,一个统一轨迹预测、控制预测与轨迹优化网络的多分支规划框架。Hydra-NeXt 引入了控制解码器以关注短期动作,使模型能更快速响应动态场景与突发行为。此外,本文还提出了轨迹优化模块,通过进一步增强并修正规划决策,有效满足了闭环环境下的运动学约束。与现有最先进方法相比,Hydra-NeXt在行为得分和完成率上分别提升了22.98%和17.49%。
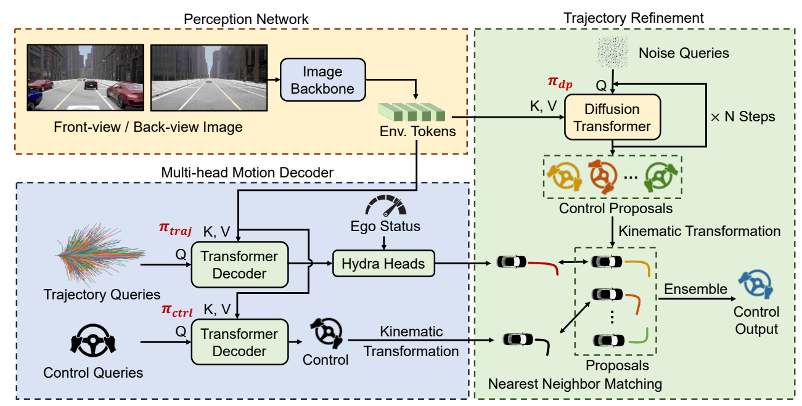
方法框架图
论文作者:
Zhenxin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Zuxuan Wu, Jose M. Alvarez
论文链接:
https://arxiv.org/abs/2503.12030
论文源码:
https://github.com/woxihuanjiangguo/Hydra-NeXt
03
VLABench:大规模复杂任务操作评测集
VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
近年来,视觉-语言-动作模型(VLA)在解决语言条件下的操作任务(LCM)方面展现出巨大潜力。然而,现有的基准测试并不能充分满足VLA及相关算法的评估需求。本文提出了VLABench ——一个用于评估通用语言条件下机器人操作任务学习的开源基准测试集。VLABench 提供了100 个精心设计的任务类别,每类任务具有高度的随机性,总计包含2000 多个对象。VLABench 在以下四个关键方面显著优于现有基准:任务需要使用世界知识与常识迁移;指令采用自然语言表达,蕴含人类隐式意图,而非模板化描述;长时序任务需要多步推理;同时评估动作策略能力和语言模型能力。该基准测试涵盖了多种能力的评估,包括对网格和纹理的理解、空间关系的推理、语义指令的理解、物理规律的掌握、知识迁移与推理等。实验结果表明,无论是当前最先进的预训练VLA模型,还是基于VLM的工作流程,仍有极大的提升空间。
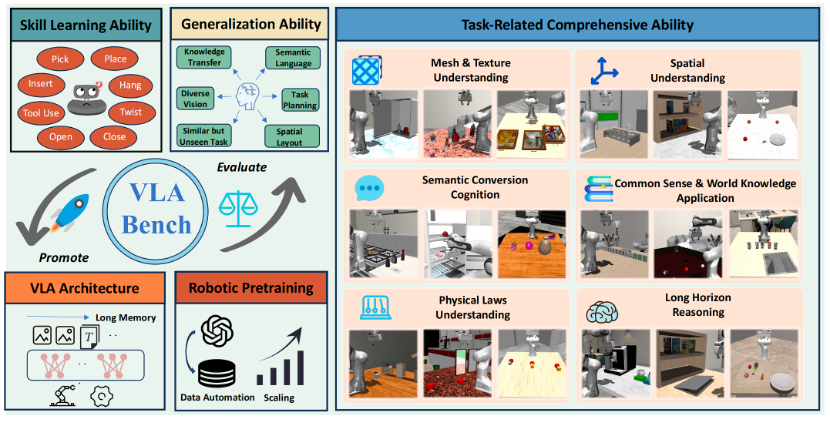
方法框架图
论文作者:
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, Xipeng Qiu
论文链接:
https://arxiv.org/abs/2412.18194
论文源码:
https://github.com/OpenMOSS/VLABench
04
从整体到局部:面向高效视觉指令微调的局部增强适配器
From Holistic to Localized: Local Enhanced Adapters for Efficient Visual Instruction Fine-Tuning
随着任务多样性和复杂性的增加,高效视觉指令微调在解决数据冲突方面面临显著挑战。为了解决这一问题,本文提出了一个全局到局部的适应性框架——“双低秩适配”(Dual-LoRA)。该框架通过双低秩结构模拟局部专家激活,从而增强适配器在解决数据冲突中的能力。此外,本文引入了视觉线索增强(VCE)模块,以提升视觉特征的质量。该方法相较于4专家LoRA-MoE推理时间减少了27%,并在多种下游任务展现了优异的性能。
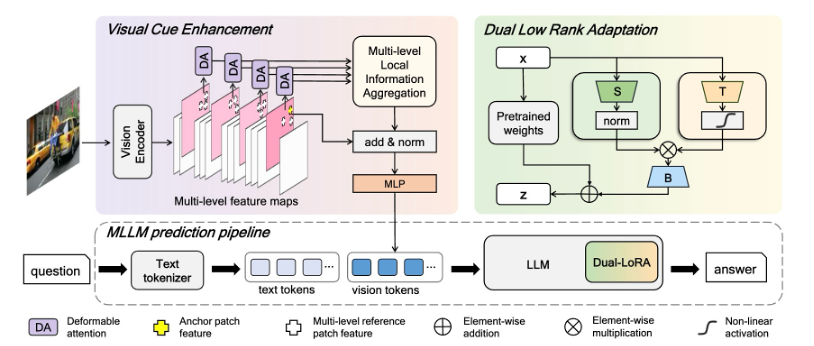
方法框架图
论文作者:
Pengkun Jiao, Bin Zhu, Jingjing Chen, Chong-Wah Ngo, Yu-Gang Jiang
论文链接:
https://arxiv.org/abs/2411.12787
论文源码:
https://github.com/pengkun-jiao/Dual-LoRA
05
面向全模态表达和推理的指代视听分割
Towards Omnimodal Expressions and Reasoning in Referring Audio-Visual Segmentation
指代视听分割(RAVS)最近取得了显著进展,但在整合多模态信息以及深入理解和推理音频视觉内容方面仍存在挑战。为此,本文提出了全模态指代视听分割数据集OmniAVS,该数据集的创新性体现在三个方面:(1) 指代指令支持文本、语音、声音和视觉线索的灵活结合,可实现8种不同多模态指令;(2) 关注对视频和音频内容的语义理解,而不仅限于音源定位或检测;(3) 表达语句中包含丰富的世界知识。此外,本文引入了全模态指令分割模型OISA,以实现细粒度的音视频内容理解。大量实验表明,OISA在OmniAVS上优于现有方法,并在其他相关任务上取得了具有竞争力的结果。

方法框架图
论文作者:
Kaining Ying, Henghui Ding, Guangquan Jie, Yu-Gang Jiang
06
事半功倍:基于加性提示调优的持续学习
Achieving More with Less: Additive Prompt Tuning for Rehearsal-Free Class-Incremental Learning
近年来,类增量学习(CIL)领域取得了显著进展,但现有方法普遍面临计算开销巨大的瓶颈。为此,本文提出了一种名为“加性提示调优”(APT)的创新策略,摒弃传统的提示池和拼接操作,采用一组轻量且在所有任务间共享的可学习提示。APT的核心思想是在Transformer的自注意力机制中将提示“加”到CLS令牌的键和值向量上,从而在不增加输入序列长度的情况下提升模型的特征提取能力。与此同时,本文引入“渐进式提示融合”策略,在推理时融合新旧任务的提示,有效缓解灾难性遗忘。实验结果表明,APT在CIFAR-100、ImageNet-R等多个主流CIL数据集上实现了“事半功倍”的效果,即在取得最先进的性能同时大幅降低计算复杂度和可训练参数量。
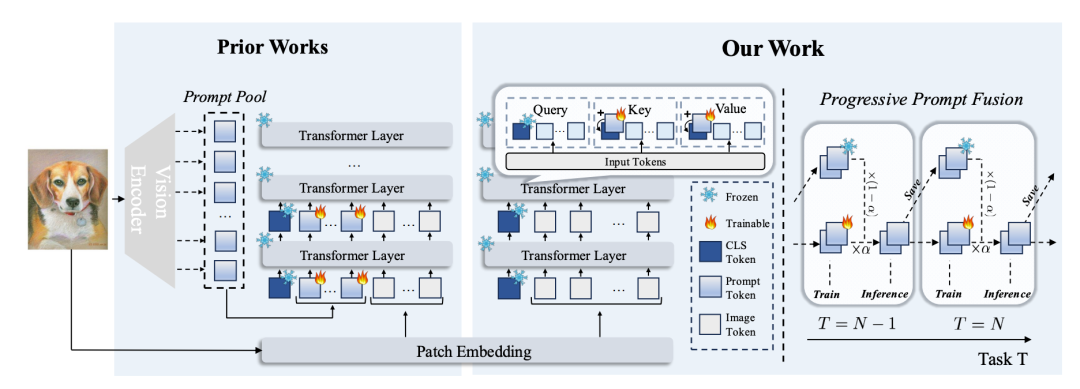
方法框架图
论文作者:
Haoran Chen, Ping Wang, Zihan Zhou, Xu Zhang, Zuxuan Wu, Yu-Gang Jiang
论文链接:
https://arxiv.org/abs/2503.07979
论文源码:
https://github.com/HaoranChen/Additive-Prompt-Tuning
07
SVTRv2:CTC在场景文本识别中超越编码器-解码器模型
SVTRv2: CTC Beats Encoder-Decoder Models in Scene Text Recognition
基于连接时序分类(CTC)的场景文本识别方法因其结构简单——仅包含视觉主干网络和CTC对齐的线性分类器——被广泛应用于OCR任务,并具备快速推理的优势。然而,相较于编码器-解码器(EDTR)方法,CTC方法在处理文本不规则性和语言建模方面存在劣势,导致准确率较低。为解决这些问题,本文提出SVTRv2,一种能处理文本不规则性和建模语言上下文的CTC模型。首先,本文提出了一种多尺寸归一化策略,将文本实例调整到合适的预定义尺寸,从而避免严重的文本变形。同时,引入了一个特征重排模块,使得视觉特征更加符合CTC解码的需求,从而缓解对齐难题。其次,本文提出了一个语义引导模块,将语言上下文信息融合到视觉特征中,使得CTC 模型能够利用语言信息提升识别准确性,且该模块在推理阶段可以被省略,不会增加推理时间。本文在传统和具有挑战性的最新基准数据集上对SVTRv2 进行了广泛评估,涵盖多种场景,包括不同类型的文本不规则性、多语言、长文本,以及是否使用预训练。结果表明,SVTRv2 在准确率和推理速度方面超过了几乎所有主流的EDTR 方法。
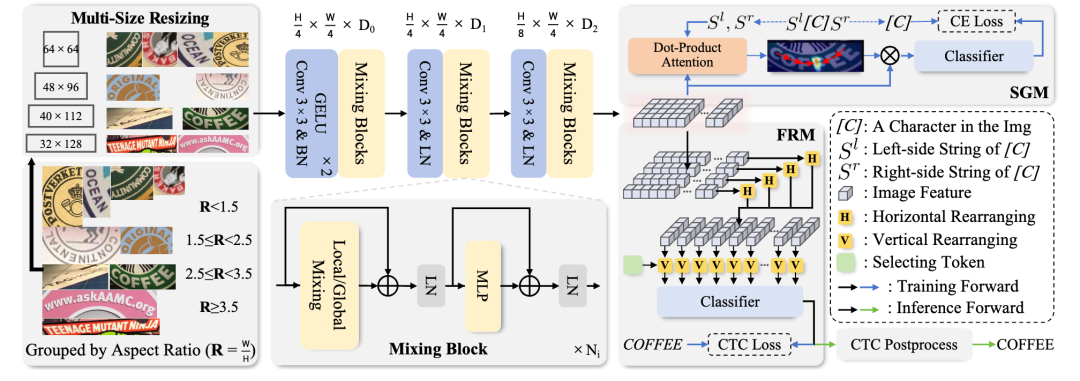
方法框架图
论文作者:
Yongkun Du, Zhineng Chen, Hongtao Xie, Caiyan Jia, Yu-Gang Jiang
论文链接:
https://arxiv.org/abs/2411.15858
论文源码:
https://github.com/Topdu/OpenOCR
08
TextSSR:面向场景文本识别的训练数据扩散生成方法
TextSSR: Diffusion-based Data Synthesis for Scene Text Recognition
受限于合成数据真实性不足以及高质量真实数据难以获取,场景文本识别模型的精度提升遭遇瓶颈。为解决这一问题,本文提出了一种高逼真场景文本训练数据生成的新方法TextSSR,其兼顾准确性、真实性和可扩展性:采用基于区域的文本生成和位置-字形增强,确保字符准确排布;利用背景上下文引导生成,使得字符嵌入更自然、更契合背景场景;基于字符级精确控制,实现了无需额外文本提示的大规模数据生成。基于上述技术,本文构建了包含355万高质量文本实例的TextSSR-F数据集。实验表明,基于TextSSR-F训练的场景文本识别模型在常用基准测试上明显优于基于现有合成数据集训练的模型,并且与真实训练数据混合使用时,可进一步得到精度更高的识别模型。
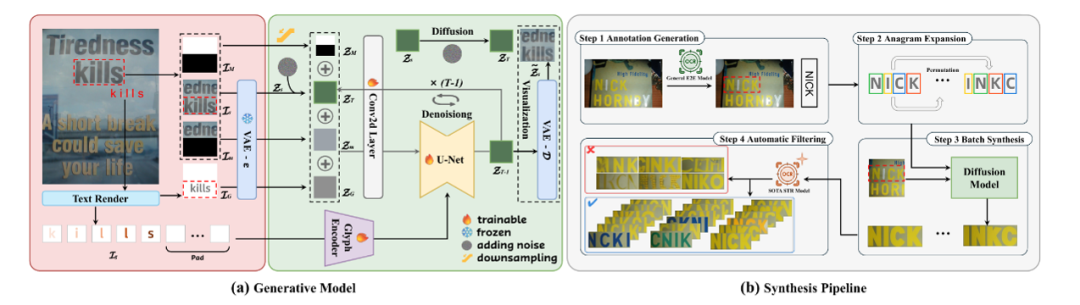
方法框架图
论文作者:
Xingsong Ye, Yongkun Du, Yunbo Tao, Zhineng Chen
论文链接:
https://arxiv.org/abs/2412.01137
论文源码:
https://github.com/YesianRohn/TextSSR
09
创意布局:基于孪生多模态扩散模型的布局可控图像生成
CreatiLayout: Siamese Multimodal Diffusion Transformer for Creative Layout-to-Image Generation
布局到图像生成任务旨在根据用户给定的布局条件(如实体的空间位置和区域描述)生成高质量、布局可控的图像,广泛应用于创意设计、广告等场景。针对这一任务,本文提出了系统化的解决方案CreatiLayout,包括三大核心部分:1)构建大规模、开放集、细粒度标注的布局数据集LayoutSAM,包含270万图文对和1070万个实体,每个实体均配有边界框和详细描述;2)设计SiamLayout结构,将布局视为一种独立模态并通过孪生多模态扩散Transformer分别进行图像-文本和图像-布局的交互,实现精准的布局可控图像生成;3)提出LayoutDesigner,基于大语言模型的微调,支持将多粒度的用户输入转换为和谐的布局。实验结果显示,CreatiLayout在空间、颜色、形状、纹理等多项指标上超越现有方法,在复杂布局条件下实现了高质量的、可控的图像生成。
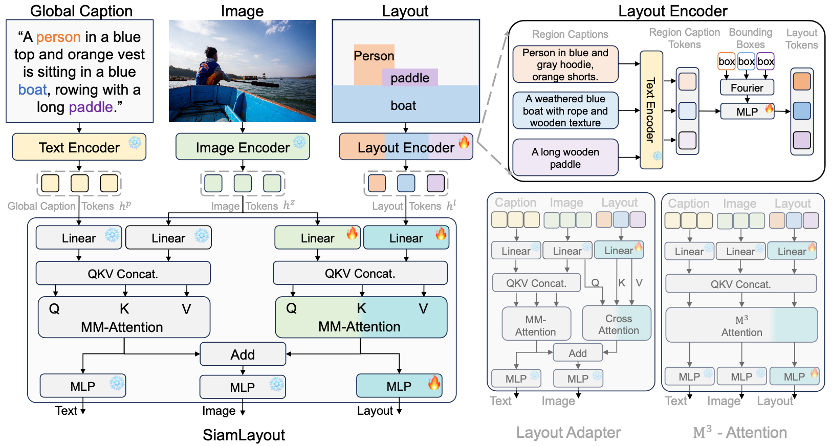
方法框架图
论文作者:
Hui Zhang, Dexiang Hong, Yitong Wang, Jie Shao, Xinglong Wu, Zuxuan Wu, Yu-Gang Jiang
论文链接:
https://arxiv.org/abs/2412.03859
论文源码:
https://creatilayout.github.io
10
基于轨迹控制的视频生成
Controllable Video Generation with Dense-to-Sparse Trajectory Guidance
近年来,轨迹可控的视频生成技术逐渐兴起,旨在实现物体运动的精确建模与控制。然而,现有方法在处理复杂或多物体运动时仍面临诸多挑战,主要表现为轨迹跟随不精确、物体一致性差以及生成视频视觉质量低。此外,现有方法普遍仅支持单一格式的轨迹控制,限制了其在多样化场景中的适用性。为应对上述挑战,本文提出了MagicMotion,一个新颖的图像到视频生成框架,支持掩码、边界框和稀疏边界框这三种形式的轨迹控制,实现了对物体运动的高精度、灵活控制。此外,本文构建了大规模轨迹可控视频数据集MagicData,以及用于评估视频质量和轨迹控制精度的评测集MagicBench。大量实验结果表明,MagicMotion在多个关键指标上均显著优于现有方法,有效提升了视频生成的质量和轨迹控制的精度。
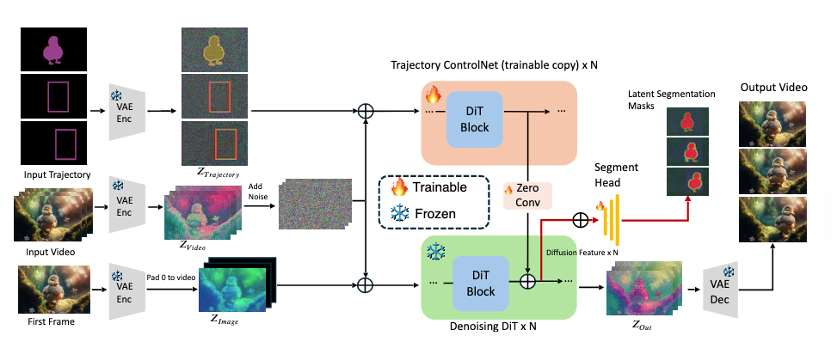
方法框架图
论文作者:
Quanhao Li, Zhen Xing, Rui Wang, Hui Zhang, Qi Dai, Zuxuan Wu
论文链接:
https://arxiv.org/abs/2503.16421
论文源码:
https://quanhaol.github.io/magicmotion-site
11
MotionFollower:基于分数引导的视频动作编辑
MotionFollower: Editing Video Motion via Score-Guided Diffusion
尽管视频编辑模型在改变视频属性方面已取得显著进展,但在修改运动信息方面的探索仍然有限。本文提出MotionFollower,一个用于视频运动编辑的扩散模型。为在去噪过程中引入条件控制,本文设计了两个信号控制器,分别用于姿态与外观建模。此外,本文设计了分数引导机制,显著提升了纹理细节与复杂背景的建模能力。实验结果表明,MotionFollower 在运动编辑任务中展现出优越的性能,无论在定性还是定量评估中均超过现有方法。

方法框架图
论文作者:
Shuyuan Tu, Qi Dai, Zihao Zhang, Sicheng Xie, Zhi-Qi Cheng, Chong Luo, Xintong Han, Zuxuan Wu, Yu-Gang Jiang
论文链接:
https://arxiv.org/abs/2405.20325
论文源码:
https://francis-rings.github.io/MotionFollower/
12
自由运动控制:视频生成中相机和物体的6D位姿生成
Free-Form Motion Control: Controlling the 6D Poses of Camera and Objects in Video Generation
以3D感知的方式控制生成视频中多物体和相机的运动是一项有意义但具有挑战性的任务。由于缺乏具有全面运动注释的数据集,现有的算法无法很好的同时模拟相机和物体的运动,导致对生成内容的可控性有限。为了解决这个问题,本文引入了带有完整6D位姿标注信息的合成数据集SynFMC。该数据集包含多样的物体和环境类别,并根据特定规则覆盖各种运动模式,模拟常见和复杂的现实世界场景。完整的6D姿态信息有助于模型区分物体和相机产生的运动效果。为了进一步验证SynFMC数据集的有效性和通用性,本文提出了一种名为FMC 的方法,基于3D 感知机制,实现对物体与相机运动的独立或联合控制,从而生成高保真、高质量的视频内容。此外,FMC还可以适配不同内容风格的个性化文生图模型。大量实验表明,FMC在多个场景中均超越现有方法。
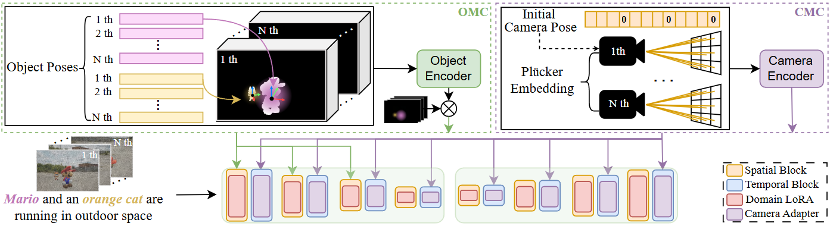
方法框架图
论文作者:
Xincheng Shuai, Henghui Ding, Zhenyuan Qin, Hao Luo, Xingjun Ma, Dacheng Tao
论文链接:
https://arxiv.org/abs/2501.01425
论文源码:
https://henghuiding.com/SynFMC/
13
基于超高压缩比自编码器的高分辨率视频生成
REDUCIO! Generating 1024×1024 Video within 16 Seconds using Extremely Compressed Motion Latents
尽管现有的视频生成模型已取得显著进展,但训练和推理成本极高。为解决这一问题,本文提出Reducio,一个基于超高压缩比自编码器的高分辨率视频生成框架,通过将视频映射至高度压缩的隐空间,从而实现高效率的视频生成。具体地,本文提出了一种以内容帧为条件的视觉自编码器,通过三维卷积在时空维度上对视频进行4096倍的下采样,并在解码阶段融入内容帧的多尺度特征以帮助重建。基于此高度压缩的隐空间,本文采用文本到图像、文本图像到视频的两阶段训练策略实现高效的视频生成。大量实验表明,本文方法显著提升了视频扩散模型在训练和推理上的效,可在15.5秒内生成16帧1024×1024分辨率的视频片段(单张A100)。
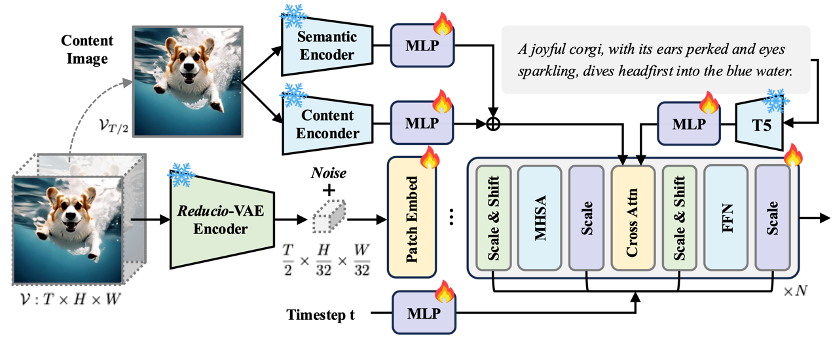
方法框架图
论文作者:
Rui Tian, Qi Dai, Jianmin Bao, Kai Qiu, Yifan Yang, Chong Luo, Zuxuan Wu, Yu-Gang Jiang
论文链接:
https://arxiv.org/abs/2411.13552
论文源码:
https://github.com/microsoft/Reducio-VAE
14
IDEATOR:VLM的自我越狱
IDEATOR: Jailbreaking and Benchmarking Large Vision-Language Models Using Themselves
现有针对大型视觉语言模型(VLM)的越狱攻击主要依赖人工设计或基于梯度的对抗图像构造,导致样本多样性和覆盖面有限。为解决这一问题,本文提出IDEATOR,一种自动化的多模态黑盒越狱框架,首创“以模型攻模型”的范式:让VLM自身担任红队角色,挖掘其内在知识与推理能力,从而生成多样化的越狱文本提示,并结合先进扩散模型合成攻击图像,从而实现高效、低查询量且具强迁移性的攻击方式。大规模实验结果显示,IDEATOR在MiniGPT-4等主流模型上达到94%的攻击成功率,并在LLaVA、InstructBLIP、Chameleon等多模型间表现出优异的迁移能力。在此基础上,本文进一步构建了大规模多模态越狱安全评测集VLJailbreakBench,覆盖3,654个高质量恶意图文对。本文基于VLJailbreakBench系统性地评估了11 个最新多模态大模型(VLM),全面揭示当前主流模型在面对恶意多模态输入时的显著安全隐患,为推动多模态大模型的安全对齐与防御机制设计提供了有力参考和全新的基准。
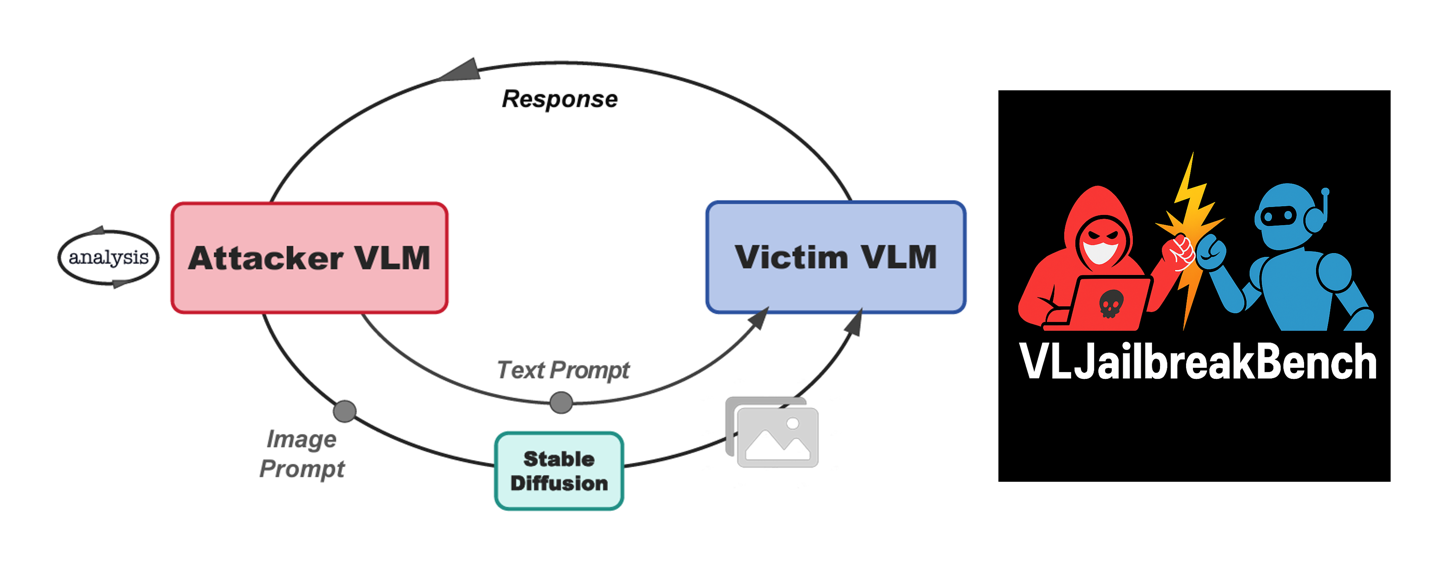
方法框架图
论文作者:
Ruofan Wang, Juncheng Li, Yixu Wang, Bo Wang, Xiaosen Wang, Yan Teng, Yingchun Wang, Xingjun Ma, Yu-Gang Jiang
论文链接:
https://arxiv.org/abs/2411.00827
论文源码:
https://github.com/roywang021/IDEATOR
15
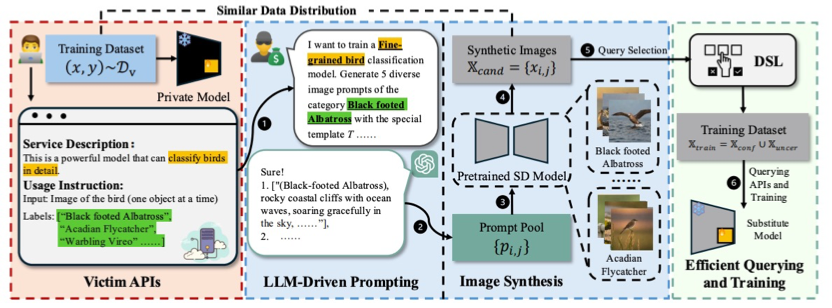
基于合成数据的LoRA 提取攻击
StolenLoRA: Exploring LoRA Extraction Attacks via Synthetic Data
近年来,参数高效微调(PEFT)方法,尤其是LoRA,极大推动了视觉模型的快速适配与定制化应用。然而,LoRA模型结构的紧凑性也带来了新的安全隐患。本文首次系统性地研究了针对LoRA适配模型的“LoRA提取”攻击,并提出了一种新型模型提取方法——StolenLoRA。该方法通过利用大语言模型自动生成高效合成数据,同时结合基于分歧的半监督学习策略,仅需有限次数的查询便能训练出高仿真“替代模型”,成功提取目标LoRA模型的核心能力。实验结果表明,即便攻击者和受害者采用不同的预训练骨干网络,StolenLoRA依然能以高达96.60%的成功率实施攻击,且仅需1万次查询。此发现揭示了LoRA类PEFT模型在现实环境下面临的独特安全威胁,凸显了针对该类方法研发专门防御机制的紧迫性。
方法框架图
论文作者:
Yixu Wang, Yan Teng, Yingchun Wang, Xingjun Ma







