
 搜索
搜索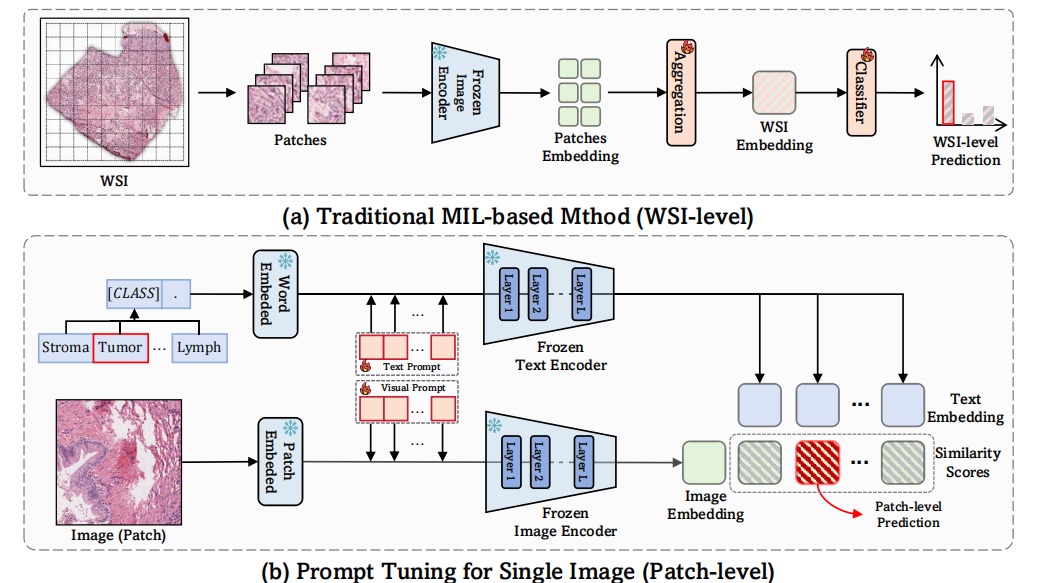

近日,复旦大学智能机器人与先进制造创新学院认知与智能技术实验室(简称CITLab)撰写的题为《MSCPT: Few-shot Whole Slide Image Classification with Multi-scale and Context-focused Prompt Tuning》的学术论文被中科院一区Top类期刊、医疗领域重要期刊IEEE Transactions on Medical Imaging(简称IEEE TMI)录用。22级直博生韩铭浩为第一作者,张立华教授为通讯作者。
论文简介:
本文依托于张立华教授牵头承担的国家自然科学基金重大项目课题-“肝癌智能化精准外科的共性关键技术体系的建立”,聚焦于利用病理图像与多模态技术服务于智能、精准的癌症术前诊断。通过提出一种新型“提示调优”策略 —— MSCPT,实现了对全切片病理图像的高效少样本分类,在多个数据集上全面超越现有方法,助力病理 AI 向临床落地更进一步。
当前存在的难点
全切片图像(Whole Slide Image,WSI) 是病理诊断的“黄金标准”,但它超高的分辨率(可达 40,000×40,000像素)意味着一个 WSI 通常包含上万个图像块。为了自动诊断这些图像,过去大家主要用多实例学习(Multiple Instance Learning,MIL)方法来训练模型。但是目前主要存在三大难题:
1.数据标注难:需要大量 WSI 才能训练出不错的模型;
2.少样本难题:稀有疾病和数据隐私限制,让数据获取困难;
3.现有方法“不够聪明”:现有 Prompt Tuning 方法大多是给自然图像设计的,没法处理复杂的病理多尺度结构和上下文信息。
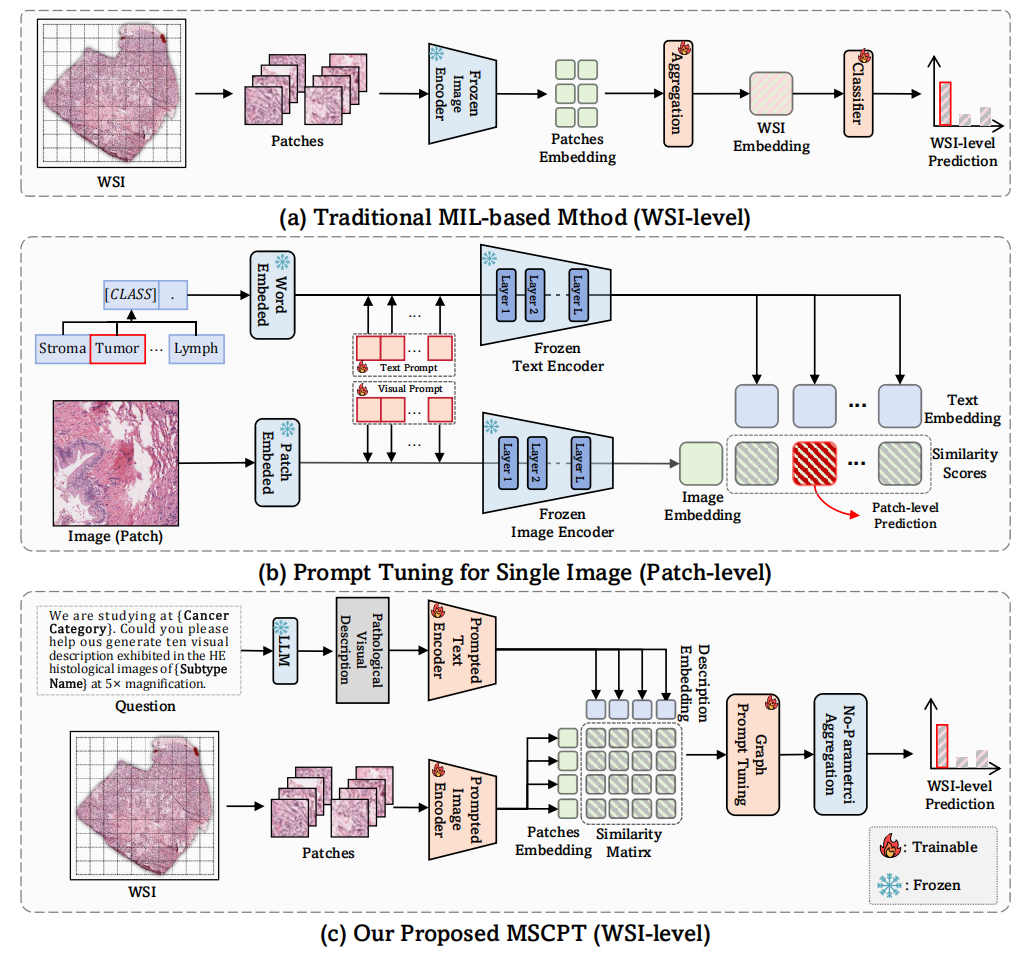
图 1 传统MIL,自然图像prompt tuning方法和我们的MSCPT比较
我们做了什么?
我们提出了一种专为 Few-shot 弱监督病理图像分类设计的新方法 —— MSCPT(Multi-Scale and Context-focused Prompt Tuning),创新地将大语言模型强大的先验知识与多尺度视觉语言信息深度融合,主要包含三个核心创新点:
1.多尺度提示调优:结合细胞级(20×)和组织级(5×)病理视觉描述,引导模型感知关键病灶区域。
2.上下文图结构建模:创新地利用图神经网络,基于图像与文本描述的语义相似性构建图结构,捕捉肿瘤上下文特征。
3.跨尺度非参数聚合:使用 Top-K 聚合策略,结合视觉与语言信息,对关键 patch 进行可解释性聚合,提高分类鲁棒性。
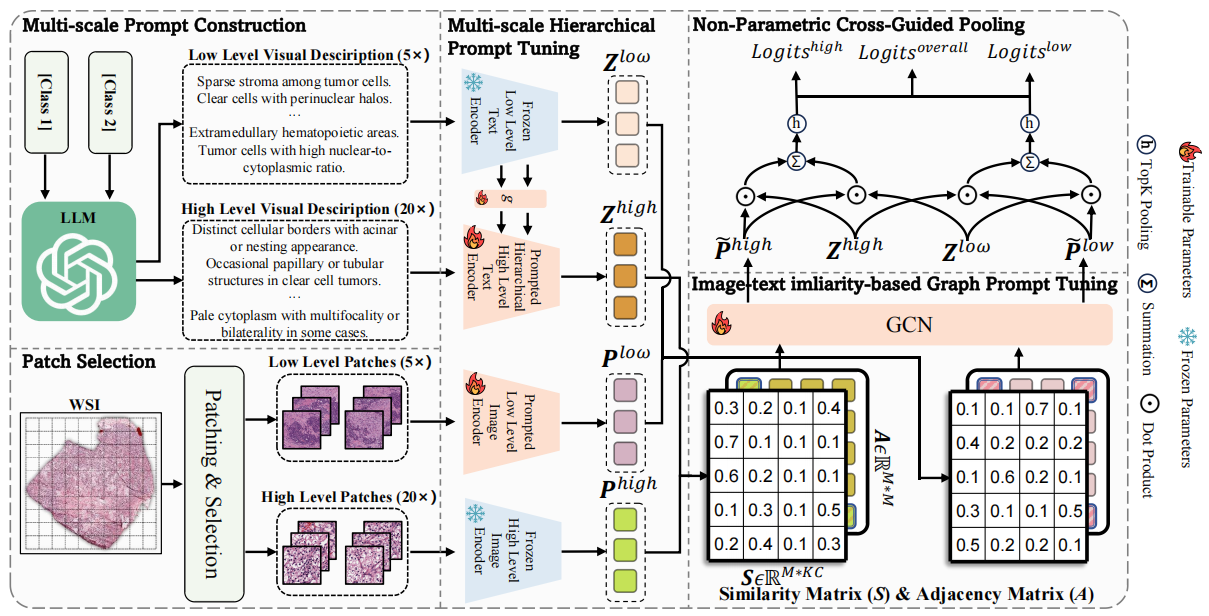
图 2MSCPT模型框架
性能表现
我们在 5 个真实病理数据集(TCGA、UBC、PANDA等)和 3 种任务类型(癌症分期分级、癌症亚型分类和癌症复发风险预测)上做了全面验证。结果显示:
1.在few-shot场景下全面领先:全面领先于其他对比方法,尤其是小样本稀缺场景。
2.极少训练参数(仅占用VLM的0.4%-0.9%参数),适配各类 VLM 模型(如 CLIP、PLIP、CONCH)。
3.兼顾性能与可解释性,为临床辅助诊断提供可读性的预测依据!
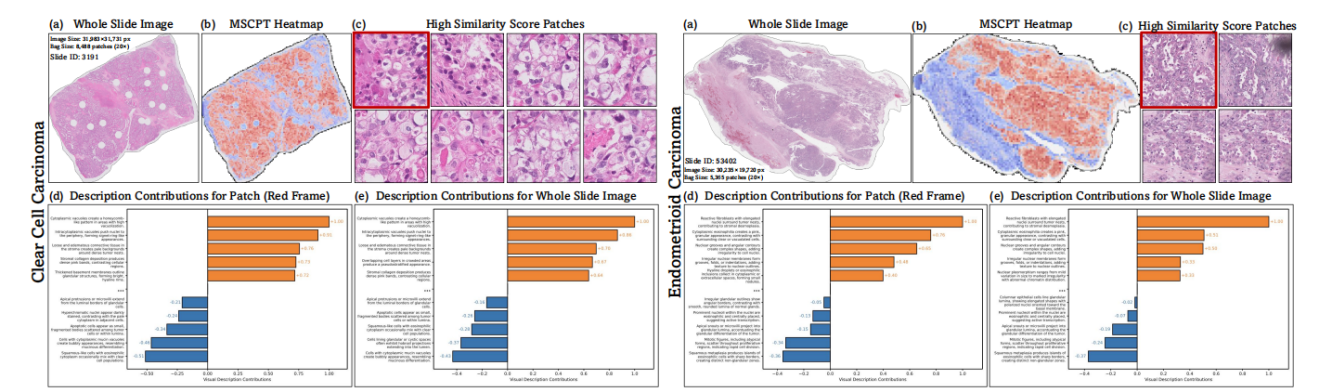
图 3MSCPT具有其他传统模型不具有的语言视觉可解释性
延伸阅读
复旦大学认知与智能技术实验室(简称CITLab)隶属于复旦大学智能机器人与先进制造创新学院、复旦大学智能机器人研究院、复旦大学元宇宙智慧医疗研究所,近年来一直在机器直觉与具身智能、物理仿真与数字孪生、多模态感知与行为识别、情感分析与大语言模型、脑机解码与人机交互以及智能机器人与无人系统、智能驾驶与智能医学等领域开展交叉创新研究,相关学术成果发表于Nature主刊、中国科学、T-PAMI、T-ITS、T-CSVT、RA-L、NeurIPS、CVPR、ICCV、ECCV、AAAI、ACM MM以及ICRA、IROS等国内外顶级学术期刊与学术会议。
IEEE TMI(IEEE Transactions on Medical Imaging)是世界范围内医疗影像与医学人工智能的重要期刊。该期刊是中科院分区一区Top类期刊。






